? All You Need to Know")
Retrieval-Augmented Generation (RAG) has been around these days and received much attention from the developer community. So, what is it exactly? How does it work? Which benefits and challenges does it potentially bring to your business? Let’s explore them all in today’s article!
What is Retrieval-Augmented Generation (RAG)?
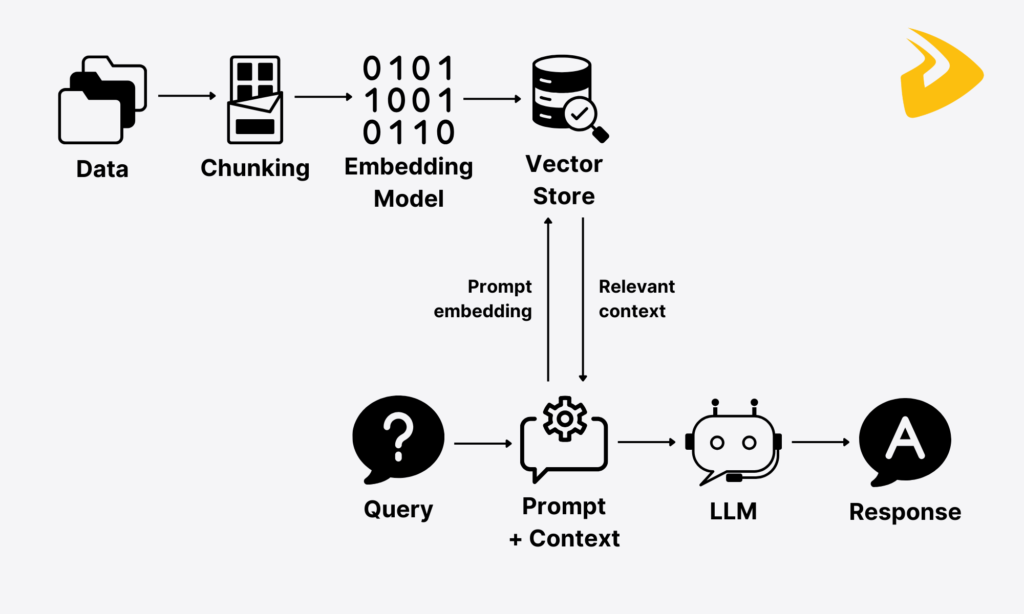
Retrieval-Augmented Generation (RAG) is a hybrid technique that combines information retrieval and text generation to create more accurate, contextually relevant responses.
This term originated from a 2020 paper conducted by Patrick Lewis and his colleagues. Accordingly, RAG models integrate more factual knowledge into LLMs (Large Language Models) without retraining them by using dense passage retrieval (DRP) to extract relevant documents for generation. This architecture solidified the hybrid systems in previous research, typically REALM, which utilized a knowledge retriever to allow language models to fetch documents from a large corpus (e.g., Wikipedia) during pre-training, fine-tuning, and inference.
As the name states, Retrieval-Augmented Generation includes two core phases:
- Retrieval: This stage receives and extracts relevant information from external data sources (e.g., your company’s internal knowledge base) that fits a user’s query.
- Generation: The LLM application (aka. “the generator”) receives the extracted information and generates contextually relevant and factually grounded responses.
RAG in AI
In the field of AI, RAG is an important approach that improves the capabilities of LLMs, especially in knowledge-intensive tasks (e.g., answering complex questions that require factual information).
Instead of solely depending on its training sources to generate responses, an LLM uses RAG to access external sources of authoritative knowledge (e.g., internal policy manuals, chat logs, or PDFs) and answer open-ended questions with factual grounding. The integration of RAG improves the quality of LLM-generated output by supporting the model with the most current and relevant facts.
How Retrieval-Augmented Generation Works
Now, let’s take a closer look at how RAG works in practice:
1. Data Collection & Preparation
If you want a RAG system to solve any query, it needs raw data or knowledge from defined, external sources, like your company’s internal policy documents or CRM. The system can directly pull the knowledge from these sources through document loaders of LangChain or LlamaIndex, like `WebBaseLoader` or `SimpleDirectoryReader`. Since these sources often contain unstructured or semi-structured data, these document loaders help pre-process the content in a more structured format like JSON.
2. Indexing & Chunking
Embedding models and retrieval systems struggle to absorb the entire content of a long document due to their context window limits (“limited size”). For instance, embedding models like e5-large-v2 only process a maximum of 512 tokens at once. Therefore, breaking down long documents into smaller, meaningful pieces (”chunks”) is a must. This process is often known as “chunking.”
3. Embeddings & Vector Databases
Embedding is the process of transforming each chunk of data into a vector representation (a ”numeric format”). The vector captures the chunk’s semantic meaning – in other words, the relationships and context of words.
Once textual data is transformed into embeddings, they’re stored in a specialized database, known as a vector store. Unlike traditional databases that process row-and-column data, vector stores excel at handling high-dimensional vectors and performing similarity searches swiftly. Some common vector databases include Milvus, Pinecone, and Weaviate.
4. Retrieving Relevant Information
When a user sends a query, this query is also converted into embeddings. Then, the retriever can compare the embeddings of both the query and stored chunks to compute how relevant they are instead of only looking at the same words. This allows the system to intelligently retrieve information, even when the stored text and the user’s query use different wordings. For example, when a user asks about “cars,” the retrieval system can extract sections about “automobiles” as their embeddings are close in a vector space.
5. Augmenting the LLM Prompt
The LLM can’t generate your desired responses if you don’t tell it exactly what to do. That’s why you need to create a good prompt template to guide how the LLM should produce a response. You can write your one manually or use pre-built templates from, for example, LangChain. Below is an example of how a prompt template works:

Source: LangSmith
After the retriever extracts the most relevant chunks, such retrieved information and the original query are fused into a single prompt and passed to the generator (LLMs).
6. Generating the Final Response
With all the “ingredients” and “instructions” above, the LLM will generate factual, contextually relevant responses for a user’s query.
Types & Architectures of RAG
So, how has RAG evolved over time? In this section, we’ll further explain the evolution of this technique over time, starting with Naive RAG:
Naive RAG
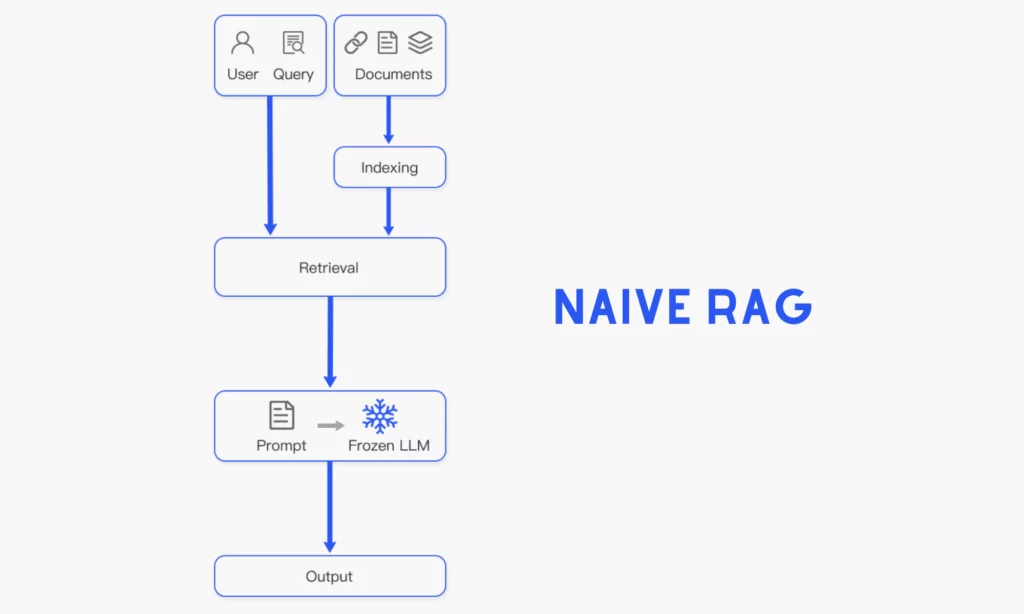
This is considered the earliest version of RAG, which covers the typical workings we mentioned in the previous section. But to differentiate it from other advanced RAG models, some researchers summarize its process into three main stages:
- Indexing: Cleaning, embedding, and organizing raw data from defined, external sources, like a company’s internal policy documents.
- Retrieval: Searching and extracting the most relevant information based on an input query.
- Generation: Fusing the original query and the retrieved data into a single LLM prompt to let the LLM generate a final, customized response. In case of ongoing dialogues, the necessary conversational history can be incorporated into the prompt to help the LLM perform multi-turn conversations effectively.
Some research indicated that Naive RAG still presents some challenges itself. The first problem comes from the retrieval process, in which the RAG system may fetch unimportant or misaligned information. This may be because:
- A single retrieval step isn’t enough to get all the necessary context for a user’s query.
- It’s quite challenging to evaluate whether the retrieved information is important or relevant to the query.
- The queries themselves are too specific or too broad for the RAG system to understand and retrieve the top K chunks.
Even with good retrieved chunks, the LLM model can still produce hallucinated facts, biased outcomes, or toxic responses. Besides, information retrieved from different data sources may not work together smoothly, producing augmentation hurdles and incoherent responses.
To resolve these limitations of Naive RAG, researchers have developed its advanced versions. They include Advanced RAG and Modular RAG.
Advanced RAG
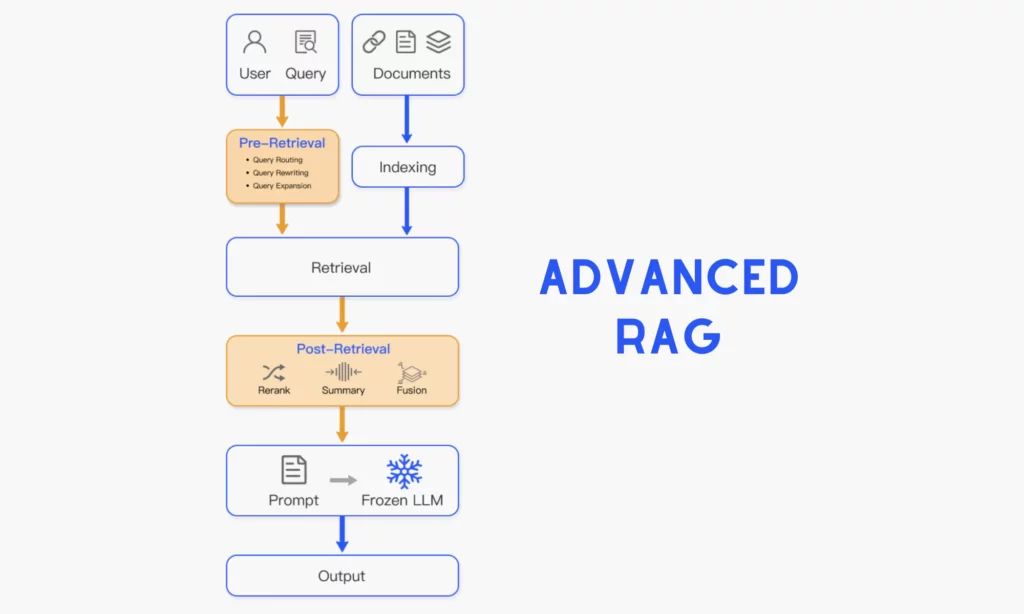
This RAG model focuses on optimizing the retrieval process by adopting advanced techniques before, during, and after this phase.
Pre-retrieval: This process is added to the traditional RAG process to improve the indexing of external documents and queries before the retriever performs any search.
- For external data sources: Some techniques are applied for better indexing, such as metadata integration, multi-representation indexing, RAPTOR (hierarchical indexing knowledge tree), or ColBERT (for token-level precision).
- For query optimization: Sometimes, the challenge comes from queries themselves, which are ambiguous for the RAG system to understand. Accordingly, the Advanced RAG system adopts common techniques like query rewriting, query expansion, and query transformation to make a user’s query clearer and easier for later retrieval. Further, the RAG system integrates logical and semantic routing to direct the incoming query to the right data source or restructure it for enhanced retrieval.
During & After Retrieval: This process ensures that the retrieved information is the most relevant, accurate, and suitable before reaching the LLM. Some common techniques in this process include Re-Ranking (re-ordering the retrieved content based on their relevance to the user’s query) and Context Compression (removing irrelevant/redundant information to avoid prompt overload).
Modular RAG
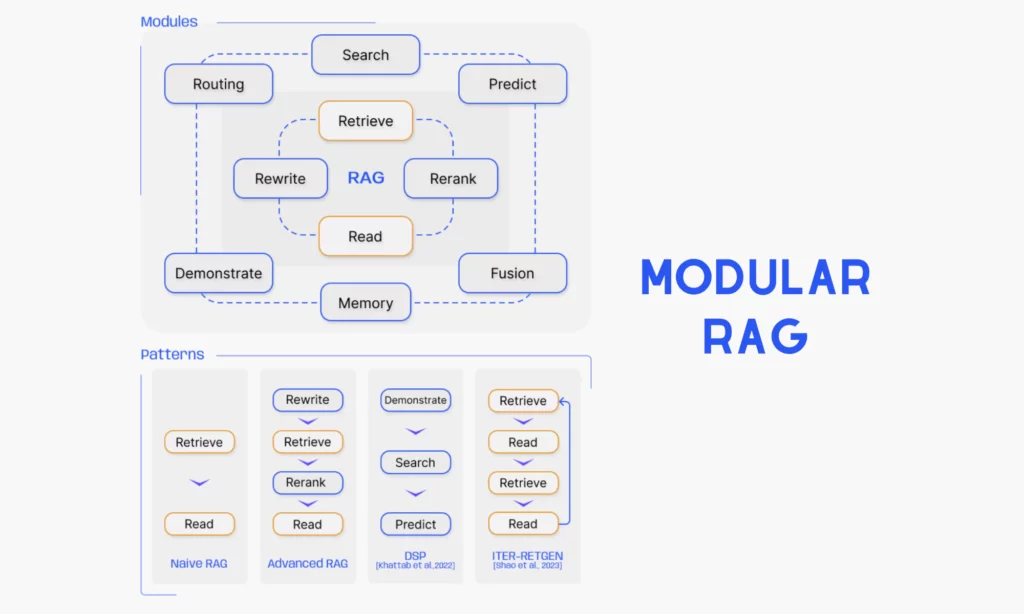
This is a more advanced framework that goes beyond the fixed structures of Naive RAG and Advanced RAG. By adding new components, the Modular RAG system can be tailored and reconfigured to address specific retrieval and generation problems. As can be seen, its architecture includes two core sections:
New Modules help Modular RAG improve its retrieval and processing capabilities. These novel modules include:
| Search Module | Use LLM-generated code and query languages to directly search across different data sources (e.g., databases, search engines, and knowledge graphs) |
| RAG-Fusion | Create different queries from the original user input, extract relevant documents for each query, and leverage reciprocal rank fusion (RRF) to rerank documents and fuse them into a comprehensive LLM prompt |
| Routing Module | Route a query to the right destination |
| Memory Module | Use the LLM’s memory to guide retrieval, creating a growing pool of past information and improving alignment with data over time |
| Predict Module | Enable the LLM to generate only the most relevant context for the final response, removing noise and redundancy |
| Task Adapter Module | Automatically generate prompts and retrievers to tailor RAG for specific tasks |
New Patterns refer to different strategies adopted to organize and use modules effectively. Beyond Naive RAG and Advanced RAG, other innovative strategies are introduced. For example, Rewrite-Retrieve-Read enhances retrieval by first rephrasing a user’s query and then using the LLM’s feedback to fine-tune it. Meanwhile, HyDE (Hypothetical Document Embeddings) embeds a generated response and searches for real documents similar to it, thus improving retrieval relevance.
Agentic RAG & RAG Agents
Everyone is talking about agentic AI as the next evolution after generative AI in 2025. And now, this advanced technology is gradually being deployed in RAG to enhance the system’s capabilities. Accordingly, agentic RAG systems do more than retrieval and generation. They can proactively adapt to new data, assisting with specific tasks or working independently. For example, RAG agents in customer service not only tell you about the refund policy, but also retrieve exact information for your specific orders.
The integration of agentic AI into RAG makes the system more intelligent and reliable, especially in scenarios where data evolves over time. Some powerful agentic RAG frameworks include DB GPT, GPT RAG by Azure, MetaGPT, and Qdrant Rag Eval.
Benefits of Retrieval-Augmented Generation

According to Predence Research, the global value of Retrieval-Augmented Generation (RAG) will reach $1.85 billion in 2025 and then witness an impressive CAGR of 49.12% in the next decade. This is an inevitable result of its transformative benefits:
Provides Up-to-Date Information
We all know that large language models (LLMs) are trained on vast corpora that have a cutoff date. These LLMs depend entirely on their internal representations of knowledge and don’t proactively update the latest information. So, it’s no wonder that their answers may be outdated and contextually incorrect. But with RAG, your LLM-powered apps can easily stay updated with new and factual data by retrieving it from external sources and generating up-to-date responses.
Reduces Hallucinations in LLMs
One of the biggest limitations in LLMs is hallucinations. Particularly, they tend to make up responses that look plausible but are actually incorrect by sifting through their pretraining corpus and finding superficially suitable information for the queries. In areas where information accuracy is paramount (e.g., medical diagnosis or legal advisory), fabricated responses aren’t encouraged. RAG reduces this problem by grounding LLM-generated answers in verified, updated documents. This enhances the factual reliability of outcomes.
Builds User Trust
RAG systems cite their sources in the retrieved documents. This allows users to validate the information in their responses, improving transparency in the answer-generating process. Over time, consistent accuracy and evidence-backed responses give users more confidence in using RAG-powered apps for different knowledge-intensive tasks (e.g., question answering or summarization).
Improves Personalization & Accuracy
Another significant motivation to use RAG lies in its ability to generate customized, accurate responses by using user- or company-specific data (e.g., a user’s past interactions or a company’s policy manuals). This allows it to handle specific tasks that require highly relevant and contextualized answers, such as those about a bank’s loan rates or a legal company’s internal compliance procedures.
Cost-Effectiveness & Developer Control
Imagine RAG as a book that your employees (aka “LLMs”) can access and retrieve valuable information to complete specific tasks. Instead of retraining LLMs with new or evolving knowledge from scratch, what you need to do is to integrate defined data sources into the models using RAG techniques. This approach is cheaper and faster. Besides, developers can control which data sources are incorporated, the retrieval techniques, and the scope of the context transferred to the models. This allows for better control over generated responses.
Getting Started With Retrieval-Augmented Generation
Retrieval-Augmented Generation is powerful and brings various benefits. However, setting it up requires the right tools, a clear implementation plan, and an effective way to measure the success of your RAG project. This section will help you with that!
Tools & Frameworks
There are a multitude of tools and stuff to do if you decide to build a RAG-powered system from scratch. But the fastest and most efficient way to develop RAG apps is to leverage available, proven frameworks, typically LangChain. This open-source framework, written in Python and JavaScript, is well-known for its modular design and a variety of tools and integrations, like document loaders, retrievers, and embedding models. Accordingly, it allows developers to build a RAG chatbot by chaining suitable components. Other alternatives to LangChain include LlamaIndex and Haystack.
Although frameworks such as LangChain integrate various tools, it’s crucial to select the right ones for your project. Consider the project scope, data types, and flexibility requirements. This will help you identify which chat models (e.g., Google Gemini), retrievers, vector databases, and other tools to use.
Implementation Roadmap
This step-by-step guide offers you a clear roadmap to implement the RAG project effectively:
- Identify your use case. Which existing problem do you want RAG to help with? Is it answering employee support questions from internal policy manuals or creating product recommendations from catalog data?
- Collect and prepare data. Identify defined data sources (e.g., databases, APIs, or documents) you want to retrieve the information from to resolve the mentioned problems. Make sure your data is up-to-date, relevant, and clean.
- Choose the right tools. Select frameworks, LLMs, embedding models, vector databases, and more that suit your project’s requirements.
- Ingest and index data. Leverage document loaders to pull data from the selected sources, then transform it into numerical representations, and store them in a vector store.
- Set up the retrieval pipeline. Choose a retriever that can fetch the most relevant chunks for a user’s query.
- Integrate the LLM. Choose the right language model and connect it with the retrieval pipeline so that the model can combine retrieved information with generative reasoning.
- Test and refine. Run multiple queries, evaluate how responses are relevant to the given query, and adjust retrieval parameters. Also, leverage techniques like RAGAS Scoring and RAG Triad to evaluate the RAG system’s performance effectively.
- Deploy and monitor. Ensure your RAG system is accessible to the target users and monitor its performance over time for improvements.
Calculating ROI of RAG Projects
RAG is beneficial, but possibly not for every business and use case. For this reason, you should calculate whether a Retrieval-Augmented Generation system delivers value to your business before committing to any resources. Here’s what you need to do:
- Identify success metrics. Depending on specific use cases, success metrics vary. For example, for RAG systems in customer support, metrics can involve faster response times, higher resolution rates, and improved customer satisfaction scores.
- Calculate cost savings. Estimate how much time and labor RAG can save compared to manual processes over a period of time. Suppose customer service agents spend 5 hours per week searching for information, and RAG can reduce that to 1 hour. Then, multiply the saved time by labor costs to calculate possible savings.
- Consider implementation costs. Calculate how much it costs to build a RAG system to meet your company’s needs. These costs may cover developer time, vector database hosting, API usage, ongoing maintenance, etc.
- Estimate revenue impact. The adoption of RAG may enhance or introduce new capabilities, such as improved sales conversions, more personalized marketing, or faster complaint resolution. Then, calculate potential revenue gains based on industry benchmarks.
Implementing Your RAG Project Successfully With Designveloper
Struggle with your RAG project and need help from experts? Come to Designveloper and let our highly skilled developers partner with your company in the RAG journey! We have extensive technical expertise in 50+ modern technologies to build custom, scalable solutions for clients across industries, from finance and education to healthcare. We also actively integrate emerging tools, like LangChain, Rasa, AutoGen, and CrewAI, to deliver intelligent solutions that work reliably while ensuring complete data privacy and security.
Here at Designveloper, our developers have been experimenting with RAG techniques in Lumin. This is a document platform that enables users to view, edit, and share PDF documents smoothly. It integrates with cloud storage services to facilitate access and collaboration on documents, wherever users live. The integration of RAG is expected to enhance Lumin’s capabilities by allowing users to query and interact with their documents using natural language. This will simplify complex PDF editing tasks and reduce difficulties in real-time document collaboration.
With our flexible Agile process and dedication to high-quality results, we commit to delivering every project on time and within budget. Do you want a further discussion on your idea? Contact our sales reps and receive a detailed consultation!
Challenges & Future of RAG

Despite the promise of RAG systems, some challenges still exist and require attention. Besides these limitations, you should consider the potential future direction of these models. This gives you good preparation for the effective adoption of RAG models in the long term:
Integration Complexity
Connecting a retrieval system to an LLM is considered challenging. But this problem becomes trickier when your RAG system pulls data from various sources (e.g., databases, PDFs, APIs) in different formats (e.g., text, images). However, the data must be consistent before being fed into the RAG pipeline, while the embeddings must be uniform for the LLM to understand correctly.
To resolve this limitation, you should build separate modules for each data source, like one module for web pages and another module for PDFs. Each module pre-processes the data so that it can have the same format and uses a standardized embedding model to generate vectors from all sources in the same way.
Data Privacy & Security
RAG systems store and index data from different sources for later retrieval and generation. However, if your external data source contains confidential or sensitive data, like personal information, proprietary documents, or trade secrets, the retrieval system may accidentally send them to unauthorized users. This can lead to serious consequences such as data leakage or compliance violations, especially in highly regulated industries like healthcare, finance, or legal services. Further, RAG systems often rely on databases, vector stores, or APIs. If any of these components are insecure or improperly configured, criminals can gain access to the data for bad purposes.
To mitigate these challenges, you should adopt role-based access control, robust encryption practices, strict logging, and data reduction. This allows only authorized users to see confidential or sensitive results and ensures every access is traceable.
Scalability
When RAG is adopted in increasingly large-scale applications, scalability will become a big concern. In this case, the demands for both retrieval and generation often grow exponentially. Not to mention that large-scale deployments often involve diverse databases, APIs, or document repositories. So when these grow in size, the retrieval system has to sift through millions or even billions of documents while ensuring high response times. This will put a heavy load on vector databases and search infrastructure.
And what if thousands or millions of users query the system at the same time? RAG systems struggle to handle high throughput, consequently slowing down or crashing. Especially in applications where real-time responses are crucial (e.g., customer service or medical decision support), users expect sub-second responses. But when the system scales, keeping retrieval and LLM generation that fast is more difficult.
To reduce this problem, future research should pay more attention to developing techniques (like distributed computing or efficient indexing) to handle increasingly large data sets and improve the efficiency of RAG models.
Emerging Trends & Research Directions
Despite these limitations, we predict RAG will still thrive in the future and play a significant role in knowledge-intensive tasks. Along with its growth are outstanding trends and research directions as follows:
- Multi-modal integration: The integration of text, image, audio, and video data into RAG models will be further researched. Accordingly, researchers will focus more on how to improve multi-modal fusion techniques to allow for smooth interactions between different data types.
- Personalization: Future RAG models will focus on customizing retrieval processes to adapt to individual user preferences and context. This involves understanding a query’s context and sentiments and adopting retrieval strategies based on user behavior, preferences, and history.
- Advancements in retrieval mechanisms: In the future, RAG systems will adopt retrieval mechanisms that dynamically adapt to evolving query patterns and content requirements. Accordingly, RAG models can actively update their retrieval strategies based on new information and changing user needs.
- Integration with emerging technologies: In the future, RAG systems may incorporate other advanced technologies like brain-computer interfaces (BCI), AR, or VR to improve user experience and create contextually aware responses.

Although Retrieval-Augmented Generation has been around for the last few years, many tech companies have jumped into this playground and offered technological support to build seamless RAG systems. If you’re new to RAG, these are the top tools and frameworks for RAG to consider:
1. LangChain
LangChain is one of the most popular frameworks used to develop LLM-powered applications. In other words, it simplifies LLM app development by offering a structured environment, modular architecture, and various components (aka “tools” and “integrations”).
How? LangChain integrates components, like language models, document loaders, vector databases, retrievers, and embedding models. Accordingly, you can select and chain the components necessary for your project’s requirements to create complex, multi-step development workflows. This modular design allows you to connect with external data sources and create AI chatbots with memory that retrieve live data and generate contextually relevant responses.
LangChain also offers LangGraph to build agentic workflows and LangSmith to inspect and evaluate your RAG system’s performance.
2. LlamaIndex
llamaIndex is an open-source framework that builds and connects LLM-powered knowledge bots with your enterprise data. It aims to simplify the process of ingesting, parsing, indexing, and processing your data. With LlamaIndex, you can develop RAG applications, where LLMs are supplemented with factual data from your knowledge base to enhance their responses and avoid hallucinations.
Some common use cases for LlamaIndex are question-answering, document understanding and data instruction, autonomous agents, multi-model applications, fine-tuning models, and chatbots. Like LangChain, the framework also integrates multiple tools and capabilities to improve the process of context augmentation through a Retrieval-Augmented Generation pipeline. This framework is now available in Python and TypeScript.
3. Haystack
Haystack is an AI orchestration framework built by deepset to allow Python developers to develop authentic LLM workflows powered by LLMs. Whether you want to build scalable RAG systems, multi-modal applications, or autonomous agents, Haystack offers a wide range of tools and integrations to turn your AI ideas into production-ready solutions. Further, the framework provides a modular architecture to help you customize built-in components (e.g., retrievers, generators, and agents) or create your own while controlling your technology stack.
You can build Haystack applications directly in Python with the support of deepset Studio, or scale up the enterprise-grade infrastructure on the deepset AI platform. Haystack also integrates built-in tracing, logging, and evaluation tools to monitor and optimize your AI applications easily.
4. Milvus
Mills is an open-source, high-performance vector database developed by Zilliz to build generative AI applications. The database is capable of handling huge datasets with tens of billions of vectors. Additionally, it has a scalable architecture and multiple capabilities that help speed up and unify similarity searches across sources.
Milvus is now available in several versions. The most lightweight version for learning and prototyping is Milvus Lite, followed by Milvus Standalone, Milvus Distributed, and Zilliz Cloud. All these versions are highly applicable in NLP applications, recommendation systems, image and video searches, drug discovery, fraud detection, and more.
5. MongoDB Atlas Search
MongoDB Atlas Search is a full-text search capability integrated within the MongoDB Atlas (a fully managed cloud database service for MongoDB). It enables you to perform advanced searches directly on your data stored in Atlas, removing the need to run and monitor a separate search system.
This search functionality allows for enterprise-grade searches by automating provisioning, patching, scaling, and disaster recovery while offering robust security and deep visibility into search operations and database performance. It also optimizes computing resources to scale search and database needs independently, improving performance and reducing 60% query times.
6. HuggingFace Transformers with RAG
HuggingFace Transformers is an open-source Python library. It allows developers to access thousands of pre-trained Transformers models and simplify the implementation of these models for machine learning tasks.
The RAG architecture is integrated within the HuggingFace Transformers library to enhance the capabilities of retrieval (e.g., using a question encoder for DPR) and generation (e.g., leveraging a seq-to-seq model like T5 or BART). This integration allows you to develop RAG systems that can access and use external data sources to enhance the quality and factual accuracy of knowledge-intensive tasks like question answering. Further, you can also fine-tune the entire RAG system on specific datasets to ensure its optimal performance for a particular task.
7. Azure Machine Learning RAG
Azure Machine Learning is a cloud service that offers multiple tools and services to speed up and manage the machine learning project life cycle. It now supports RAG by tightly incorporating Azure OpenAI for LLMs and embeddings and with vector databases (e.g., Azure AI Search and Faiss). The platform also integrates with open-source data processing tools like LangChain to chunk and process external documents.
Beyond these core components, Azure Machine Learning offers other features to enhance the RAG process, such as quick-start samples for common RAG-based question-answering use cases it Wizard UI for uploading, monitoring, and connecting data into LLM prompts. Besides, the platform has built-in evaluation tools to measure RAG workflows, generate test data, automatically create prompts, and visualize metrics.
8. IBM Watsonx.ai
IBM watsonx.ai is a one-stop AI development studio. It offers a comprehensive suite of preconfigured SDKs, APIs, RAG frameworks and templates, developer-focused capabilities, and more to develop different AI applications, from RAG systems to agentic AI workflows.
The studio offers two ways for RAG system development. Developers can write their own RAG system by using the Python library, Node.js SDK, and REST API. Meanwhile, those without coding skills can use no-code/low-code tools, including Prompt Lab and AutoAI RAG, to build RAG pipelines for improved accuracy and performance. Prompt Lab allows you to chat with uploaded and indexed documents or vector indexes, while AutoAI RAG automatically generates multiple pipeline configurations, and then evaluates and ranks their performance.
9. ChatGPT Retrieval Plugin
The ChatGPT Retrieval Plugin is an open-source solution that allows OpenAI models (e.g., ChatGPT or custom GPTs) to access and fetch information from different documents through semantic similarity searches by using natural language queries. Further, it uses embedding models (e.g., OpenAI’s `text-embedding-ada-002`), plus vector databases (e.g., Pinecone or Weaviate) to store and query embeddings of documents.
As a self-hosted solution, the ChatGPT Retrieval Plugin can be deployed on different cloud platforms that support Docker containers (e.g., Heroku or Azure Container Apps). It also automatically updates its stored data when documents are changed, added, or deleted. Besides, you can customize the plugin by adjusting data models, authentication methods, the plugin’s name, etc.
FAQs About Retrieval-Augmented Generation
What types of data can RAG retrieve?
RAG can retrieve any type of data from different data sources, like PDFs, websites, databases, APIs, or even video transcripts. This data covers text, images, videos, and more, mainly processed and retrieved by multi-modal embedding models and retrievers.
Why is RAG better than LLM?
RAG is not exactly better than LLMs because it’s introduced to supplement these language models. The LLM alone relies only on its pre-training data sources, which may be incomplete or outdated. But RAG connects the LLM to external and updated data sources. This allows the LLM to access the latest knowledge and generate more accurate and contextually relevant responses.
Does RAG support real-time applications?
Yes. If the retrieval system is connected to a real-time data source, RAG can work in real-time. It means the system can answer questions by using the latest information, like breaking news or stock prices.
When should I use RAG instead of fine-tuning?
Fine-tuning means adjusting and updating the LLM’s core knowledge base. This technique proves more beneficial when you want the model to deeply learn a specific style, format, or niche topic that doesn’t change much. But RAG is more encouraged when your model has access to large amounts of ever-changing information. In this case, RAG is a faster way to update the latest information without retraining the model.
What is the primary goal of retrieval augmented generation?
The main goal lies in its name: Retrieval Augmented Generation. Accordingly, it aims to help the LLMs access accurate, relevant, and up-to-date information from outside their training data to generate more personalized, contextually aware, and factually grounded responses. For this reason, the LLMs will become more trustworthy and useful.


{kind=link}
Nice blog here Also your site loads up very fast What host are you using Can I get your affiliate link to your host I wish my site loaded up as quickly as yours lol