
When learning about the best vector databases in today’s era, you may hear of so many noticeable names like Pinecone, Milvus, and ChromaDB. Among them, Pinecone appears as one of the most commonly used databases for vector similarity searches. So, what is Pinecone exactly, and how can it help your AI applications find and retrieve the most relevant information? Let’s find out the fundamentals about this vector database in today’s article!

What is Pinecone? Key Concepts Explained
Before diving deep into what Pinecone is, we want to explain the key concepts regarding it, including what a vector database and vector embeddings refer to.
What is a vector database and a vector embedding?
A vector database differs from traditional databases, which contain structured data in rows and columns. As the name suggests, it stores vectors – the numerical representations of data points which are often unstructured.
When the Internet grows and humans have more chances to share or access information, we’ve witnessed an increase in unstructured data (like social media posts or customer reviews). This type of data is valuable but has no rigid structure, making it hard for traditional relational databases to organize and optimize it for specific use cases (like answering a customer’s question about return policies). For this reason, we need a more effective solution to handle this unstructured data. And vector databases come in.
No matter how smart they are, machines haven’t completely understood our natural language. Therefore, we need specialized machine-learning models like CLIP or OpenAI’s text-embedding-ada-002 to convert unstructured data into numerical vectors that machines can interpret. We call this process “embedding.” Vector databases, in this case, will store those vector embeddings.
When you send a query, this query is embedded in the same way to become a numerical vector. Then, vector databases will measure the distance between the stored embeddings and the query vector. The shorter the distance is, the closer they are. This helps vector databases identify the most relevant information even when it doesn’t use the exact same words as the query.
With this capability, vector databases help AI apps find, for example, “car-related” documents for the query of “automobiles.” For this reason, vector databases become more popular, with a CAGR of nearly 22% from 2025 to 2034.
What is Pinecone and its role?
Pinecone is such a vector database. As a cloud-native vector database, it aims to store, index, and search for high-dimensional embeddings that represent any data type, like text, images, or audio. The database is built on a serverless architecture, which allows your team to easily scale and manage vector search applications.
Key Features and Benefits of Pinecone
Pinecone is one of the most popular vector databases as it brings the core capabilities and benefits for high-speed similarity searches, as follows:
Fully managed & serverless
Pinecone is a fully managed and serverless solution. It handles the complexity of deploying and managing the underlying infrastructure, as well as automatically scales with growing search demands or data volumes without manual server management.
Real-time indexing
Pinecone allows for real-time indexing. When you upload or update vectors, Pinecone will index them dynamically to keep searches fresh.
Low latency & high recall
Pinecone uses top-performing algorithms to maximize the number of truly relevant results (high recall) while ensuring fast search (low latency).
Diverse search methods (including multimodal search)
Pinecone not only supports semantic search, but also enables lexical/keyword search. By using sparse indexes, the vector database can look for exact words that match your query string.
Besides, Pinecone allows for hybrid search to find the most relevant results that cover synonyms, paraphrases, and even exact domain-specific terminologies.
Pinecone enables you to attach corresponding metadata (e.g., language: en) to vectors. This helps narrow search results to meet pre-defined conditions. For example, the system can find and filter “badminton rackets” within the category: Pro Ace and language: en.
Additionally, Pinecone also supports multimodal search, whether you want to find text, images, audio, or videos.
Now, Pinecone integrates multimodal embedding models (e.g., CLIP or jina-clip-v2) that mainly allow you to build a shared embedding space to contain both text and image vectors. This helps AI systems to search for images based on either visuals or textual descriptions.
Further, it connects with Marengo-retrieval-2.6 from TwelveLabs to support search tasks on any data types, including Text-to-Audio, Text-to-Video, etc.
Reranking
Pinecone improves the quality of the results with an extra reranking layer. It offers pre-hosted rerankers (e.g., cohere-rerank-3.5 or pinecone-rerank-v0) or allows you to leverage external reranking models.
After receiving the query and results, your chosen reranker will score the results based on how they’re semantically relevant to the query and return a more precise ranking. This is very useful in RAG pipelines.
Numberspaces
Pinecone allows you to manage different customers, users, workspaces, and more separately and securely in a single index by using namespaces. Namespaces are like separate sections within an index.
One namespace contains all parameters of a specific tenant, and all vector data operations (like adding, deleting, querying, or updating) happen within that namespace. This feature allows you to search for the vectors of only that tenant and keep its data isolated and private.
Note: You can’t query across namespaces. So if you want to implement multi-tenant searches, use metadata filtering instead.
How Does Pinecone Work?
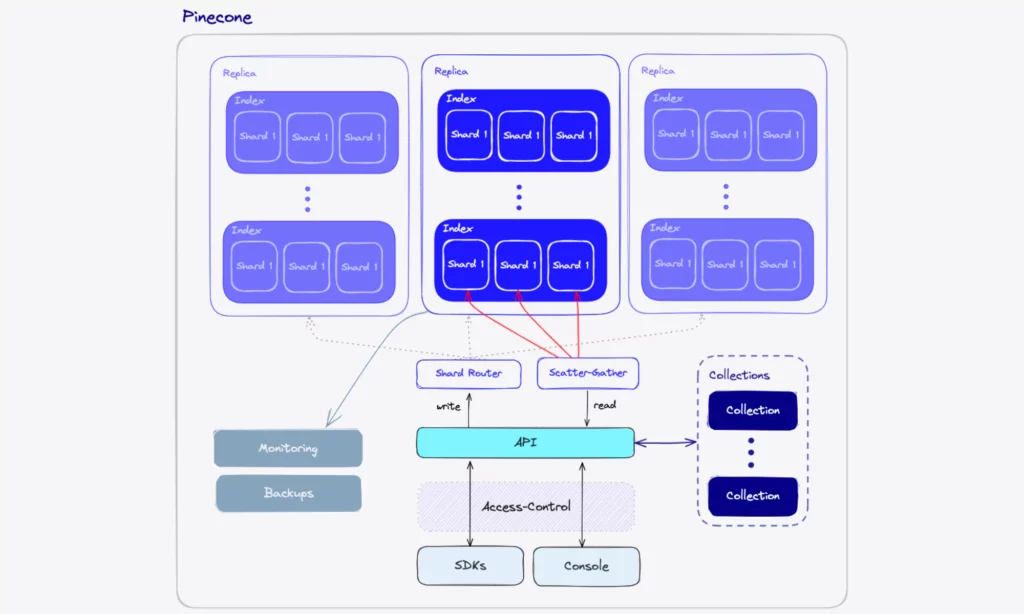
The vector database works in the following steps:
- Data preparations (or Embedding creation) – First, you need to transform the raw data into embeddings (numerical vectors). There are two ways to do so:
- Using Pinecone’s pre-hosted embedding models (e.g., NVIDIA’s
llama-text-embed-v2, Microsoft’smultilingual-e5-large, or OpenAI’stext-embedding-ada-002). - Embedding the data externally and uploading the generated vectors to Pinecone.
- Using Pinecone’s pre-hosted embedding models (e.g., NVIDIA’s
- Index Creation – Before inserting and searching for vectors with Pinecone, you have to create a Pinecone index. In Pinecone, an index contains vectors and comes into two groups: dense and sparse.
- Dense indexes keep dense embeddings (which are numerical vectors of the relationships or meaning in data) for semantic search.
- Meanwhile, sparse indexes keep sparse embeddings (which numerically represent exact words or phrases in documents) for keyword search.
- Data Ingestion – Your system inserts or updates vectors, along with metadata, to Pinecone indexes through the Pinecone API Gateway.
- Querying & Search – A user query is embedded using the same embedding model. Then, Pinecone compares the query vector against the stored embeddings and uses similarity metrics to return the most relevant results.
- Optional Hybrid & Reranking – If you need both lexical and semantic matching, run a hybrid search. To do so, you can create a single hybrid index or use dense and sparse indexes separately and merge their results. Additionally, you can adopt reranking models in Pinecone to improve the accuracy of search results.
How to Get Started With Pinecone

To get started with Pinecone, you first need to access the website pinecone.io and create a free account.
If you intend to build a personal or small-scale project, choose a free plan that offers you most features and pick your preferred language (e.g., Python, Go, JavaScript, C#, etc.). You can also customize your setup by clarifying your project scope, data size, and ultimate goals.
Once you’ve successfully created a Pinecone account, you’ll be given a “default” API key that is used when you work with the Python client of Pinecone. Then, you should follow the steps below to install and use Pinecone for similarity search:
Step 1: Install the SDK
In your terminal window, install the Python SDK or any chosen programming language:
pip install pineconeStep 2: Initialize the Python client
You need an API key to make calls to your Pinecone project. Use the following command line to get an API key:
PINECONE_API_KEY="YOUR_API_KEY"To use your API key, you must initialize a client object:
from pinecone import Pinecone, ServerlessSpecpc = Pinecone(api_key="YOUR_API_KEY")Step 3: Create an index
Pinecone allows you to create dense indexes for semantic search and sparse indexes for lexical search. To simplify this guide, we just focus on the creation of a dense index that is incorporated with an embedding model (llama-text-embed-v2) hosted in Pinecone. This integrated model helps Pinecone automatically convert textual data into vector embeddings.
index_name = "developer-quickstart-py"if not pc.has_index(index_name): pc.create_index_for_model( name=index_name, cloud="aws", region="us-east-1", embed={ "model":"llama-text-embed-v2", "field_map":{"text": "chunk_text"} } )Step 4: Upsert data
You can prepare a sample data to experiment with Pinecone. This data can relate to any topics, like history, maths, geography, and so on. In this example, you’ll upsert a text-based data sample to a new ns1 namespace in your index and the embedding model integrated into Pinecone will automatically embed it. For example:
index = pc.Index(index_name) records = [ { "_id": "rec1", "chunk_text": "The Eiffel Tower was completed in 1889 and stands in Paris, France.", "category": "history" }, { "_id": "rec2", "chunk_text": "Photosynthesis allows plants to convert sunlight into energy.", "category": "science" }, { "_id": "rec3", "chunk_text": "Albert Einstein developed the theory of relativity.", "category": "science" }, { "_id": "rec4", "chunk_text": "The mitochondrion is often called the powerhouse of the cell.", "category": "biology" }, { "_id": "rec5", "chunk_text": "Shakespeare wrote many famous plays, including Hamlet and Macbeth.", "category": "literature" }, { "_id": "rec6", "chunk_text": "Water boils at 100°C under standard atmospheric pressure.", "category": "physics" }, { "_id": "rec7", "chunk_text": "The Great Wall of China was built to protect against invasions.", "category": "history" }, { "_id": "rec8", "chunk_text": "Honey never spoils due to its low moisture content and acidity.", "category": "food science" }, { "_id": "rec9", "chunk_text": "The speed of light in a vacuum is approximately 299,792 km/s.", "category": "physics" }, { "_id": "rec10", "chunk_text": "Newton's laws describe the motion of objects.", "category": "physics" }]index.upsert_records("ns1", records)Upon upserting, you can check the index stats to see whether the current record count matches the number of records you added:
print(index.describe_index_stats())Step 5: Search & rerank
When a user query arrives, Pinecone converts the text to a dense vector automatically. Then, you can implement semantic search through the ns1 namespace to find the most relevant items and content. For example:
query = "Famous historical structures and monuments"results = index.search( namespace="ns1", query={ "top_k": 5, "inputs": { 'text': query } })print(results)To get more precise results, you can use a reranker hosted by Pinecone to rerank the results based on how relevant they are to the query. For example:
reranked_results = index.search( namespace="ns1", query={ "top_k": 5, "inputs": { 'text': query } }, rerank={ "model": "bge-reranker-v2-m3", "top_n": 5, "rank_fields": ["chunk_text"] }, fields=["category", "chunk_text"])print(reranked_results)Best Use Cases of Pinecone Vector Database

Pinecone offers a wide range of capabilities and benefits to support LLM-powered applications in performing various tasks. Three common use cases of this vector database lie in NLP (Natural Language Processing), multimodal search, and recommendation systems.
NLP: Pinecone is a crucial component in NLP systems that aim to search for semantically similar content to a user query. These systems include shopping assistants embedded in e-commerce websites or apps or self-serve knowledge assistants across sectors (e.g., healthcare or education).
By storing and looking for relevant content from a company’s internal knowledge base, Pinecone helps these smart bots return factually grounded and contextually relevant responses to user queries.
Multimodal search: Beyond text, Pinecone also supports search through other data types like images, audio, and videos.
For example, the vector database can sift through medical images to detect common disease patterns that are invisible to the naked eye or find audio transcriptions to identify the leading causes behind a customer’s complaints.
Recommendation systems: Pinecone plays an important part in recommendation systems. By comparing the stored vectors with the embedded signals (e.g., customer behaviors or browsing habits), Pinecone supports e-commerce bots in returning similar content to increase user experiences and drive sales.
How Designveloper helps you build reliable AI solutions
Many companies are integrating the latest technologies to make their bots, especially in customer service and internal knowledge assistance, smarter and more useful in looking for factually grounded and contextually relevant information.
Do you also want to upgrade your existing AI application or build a reliable AI solution from scratch? Designveloper is here to help you realize that idea!
Here, our excellent team has 13 years of hands-on experience and extensive technical expertise to build scalable, high-quality AI solutions that can integrate seamlessly with embedding models and vector databases like ChromaDB, Milvus, or Pinecone. Our solutions are built with the right tech stacks and cutting-edge technologies like LangChan, AutoGen, or CrewAI to serve your specific use cases.
Typically, we’ve developed an e-commerce recommendation system in the form of bubble chat. We also integrate LangChain and OpenAI in customer service agents to automate support ticket triage. Our dedicated solutions receive positive feedback from clients not only due to dedication to excellence but also good communication and proven Agile frameworks that ensure on-time delivery.
With our proven track record, we’re confident in creating custom AI solutions that resolve your existing problems and streamline operations. Why wait? Contact us and discuss your idea further!
Challenges of Pinecone
Pinecone is a common option for various AI use cases. But it doesn’t mean this vector database presents no limitations. Here are several features that can be considered as Pinecone’s drawbacks:
- Pinecone is a cloud-native and fully managed service. This means you can’t download and run it on your own servers like ChromaDB. This makes Pinecone a less appealing choice for strict data control.
- Pinecone stores your data in its format and APIs. If you want to move everything to another vector database, it’s tricky.
- Pinecone keeps your vector embeddings and metadata in its cloud. This can expose your data to security risks related to cloud services. So, when working with Pinecone, you must ensure that storing the data in this database meets your company’s security requirements.
FAQs:
Is Pinecone fast?
Yes. Pinecone is developed for low-latency and high-recall vector search. By using optimized indexing, in-memory techniques, and horizontal scaling, the vector database can shorten query times (to milliseconds) even when it has to sift through huge vector volumes.
Why use Pinecone with Large Language Models (LLMs)?
Pinecone is an ideal option for NLP (Natural Language Processing) or RAG (Retrieval-Augmented Generation) systems built with LLMs.
LLMs are capable of using their fed knowledge to return natural language responses (like generating social media posts or summarizing long documents). Meanwhile, Pinecone specializes in storing and searching for semantically relevant information to a user query.
With Pinecone, you can extend the inherent capability of LLMs to external data retrieval, helping them generate factually grounded and relevant answers. This makes LLMs more useful in real-world applications where information accuracy and relevance are paramount, like medical diagnosis, customer service, or legal services.
Does Pinecone use SQL?
No, Pinecone is a NoSQL vector database. You can communicate with it through a REST or gRPC API or official client libraries (e.g., Python or JavaScript). Queries are not written like SQL statements, like:
SELECT * FROM products WHERE price < 50;Instead, Pinecone searches for the most similar vectors to your query vector and applies metadata filtering to narrow down searches.
Is the Pinecone database free?
Pinecone is not an open-source vector database like ChromaDB. But yes, it offers a free plan for developers to try out this database and implement small-scale applications, with limited features.


{kind=link}