
Python best practices are the habits that make Python code easier to read, review, test, debug, and maintain over time. Good Python is not only code that runs. Good Python is code another developer can understand, change safely, and trust in production.
The most useful practices are simple: clear names, small functions, consistent formatting, clean project structure, helpful tests, careful error handling, type hints where they reduce ambiguity, and tooling that catches problems before code review. Teams get the best results when these practices become part of the development workflow instead of a checklist remembered at the end.
This guide turns Python style advice into practical engineering habits. It follows the audit outline and focuses on what matters for real projects: maintainable structure, reviewable changes, automated quality checks, and conventions that help teams scale Python codebases.

What Do Python Best Practices Actually Mean?

Python best practices are shared decisions about how a team writes, organizes, tests, and maintains Python code. Some practices come from community standards such as PEP 8 style guidance. Others come from production needs such as packaging, logging, type checking, dependency management, and review workflows.
Best practices should make code easier to change. A rule that improves readability, reduces bugs, or speeds review is useful. A rule that only creates ceremony without improving maintainability should be questioned. PEP 8 itself warns that consistency matters, but practical judgment still matters when a local convention improves clarity.
For teams, Python best practices usually answer four questions:
- Can a new developer understand this module quickly?
- Can reviewers see the business logic without fighting formatting noise?
- Can tests catch regressions before release?
- Can the project grow without becoming a folder of unrelated scripts?
A useful way to evaluate any Python rule is to ask whether it protects the next developer. The next developer may be a teammate reviewing a pull request, an engineer debugging a production incident, or the original author returning to the same module six months later. Best practices create a shared language for those moments.
Python code also appears in many different product contexts. A Django monolith, a FastAPI microservice, an AI inference service, an Airflow data pipeline, and a command-line automation script do not need identical architecture. However, all of those codebases benefit from explicit boundaries, predictable setup, meaningful tests, and quality checks that run before deployment.
For engineering teams, the best version of a Python convention is written down and automated. If the team wants imports sorted, a formatter should sort imports. AndiIf the team wants type hints on public service functions, a type checker should verify them. Finally, if the team wants a consistent folder layout, new repositories should start from a template instead of personal memory.
Write Python Code That Is Easy To Read
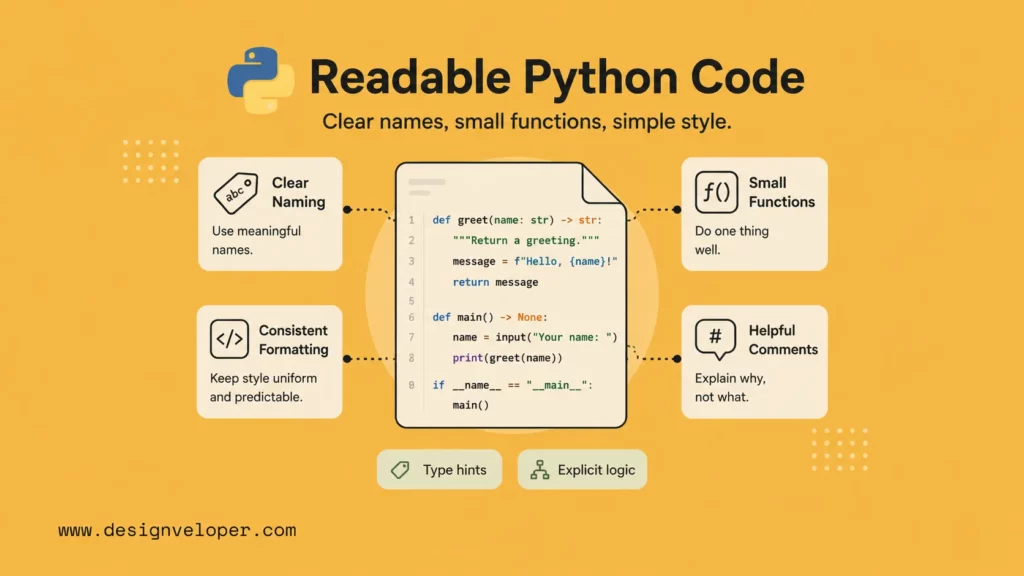
Readable Python code states intent clearly. The reader should understand what a function does, what data it expects, and what it returns without decoding clever shortcuts.
| Practice | Good habit | Why it matters |
|---|---|---|
| Clear naming for variables, functions, and classes | Use names such as calculate_invoice_total or active_users. |
Reviewers understand intent before reading implementation details. |
| Small, focused functions | Keep functions centered on one job and one level of abstraction. | Testing, debugging, and refactoring become easier. |
| PEP 8 consistency without overengineering | Use consistent indentation, imports, whitespace, and line length conventions. | Formatting stops distracting from logic. |
| Comments and docstrings only where they add real value | Explain why code exists, not what obvious code already says. | Comments stay useful instead of becoming stale narration. |
Clear names are the cheapest readability improvement. A variable named data forces the reader to inspect surrounding code. A variable named paid_invoice_rows gives the reader useful context immediately.
def process(data): return [x for x in data if x[2] > 0] def get_paid_invoice_rows(invoice_rows): return [row for row in invoice_rows if row.amount_paid > 0]Small functions also reduce hidden risk. If one function validates input, queries the database, formats a response, sends an email, and logs analytics, every change becomes harder to test. Split the work into named steps so each part can fail clearly.
One practical readability rule is to keep one level of abstraction inside a function. A function that calculates shipping fees should not also parse environment variables, open a database connection, and format an HTTP response. Mixed abstraction makes code difficult to name and harder to test.
Readable Python also avoids hidden side effects. A function named normalize_customer_email should return a normalized email address. If that same function updates the database, sends analytics, or mutates a shared object, the name hides important behavior. Side effects should be visible in names, boundaries, or documentation.
Docstrings are most valuable on public functions, complex domain rules, and modules that other teams will reuse. A short docstring can explain accepted inputs, returned values, raised exceptions, and edge cases. Internal helper functions do not need long comments when clear names and tests already explain the behavior.
def calculate_discounted_total( subtotal_cents: int, discount_percent: float,) -> int: """Return the final invoice total in cents after a percentage discount.""" if subtotal_cents < 0: raise ValueError("subtotal_cents must be non-negative") if not 0 <= discount_percent <= 100: raise ValueError("discount_percent must be between 0 and 100") discount_cents = round(subtotal_cents * (discount_percent / 100)) return subtotal_cents - discount_centsReadable code should make invalid states difficult to ignore. In the example above, validation happens close to the calculation, exceptions name the invalid input, and the return type makes the unit clear. That small amount of clarity prevents later confusion about cents versus dollars or decimal percentages versus whole-number percentages.
Structure Python Projects For Maintainability
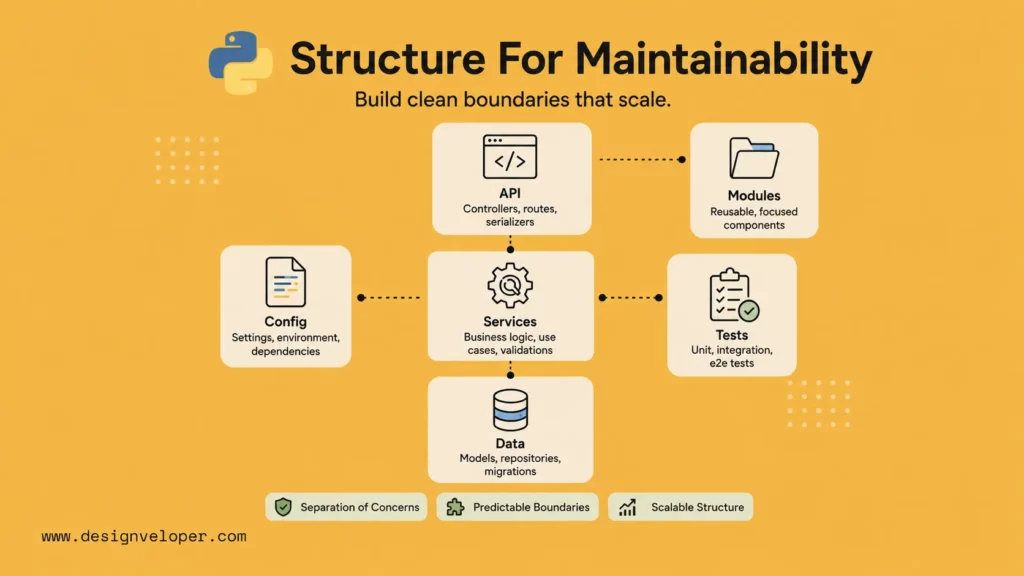
Project structure determines how quickly a Python codebase can grow. A tidy structure separates application logic, configuration, tests, scripts, and shared utilities so developers can find the right file without guessing.
For packages and applications that may grow, the Python Packaging User Guide discussion of src layout explains why putting importable code under src/ can help avoid accidental imports from the project root. The right layout still depends on the project, but teams should choose a convention deliberately.
example_project/ pyproject.toml README.md src/ example_app/ __init__.py config.py services/ repositories/ api/ tests/ unit/ integration/ scripts/ docs/Separate business logic, configuration, and utilities early. Configuration should not be scattered across modules. Utility code should not become a dumping ground. API routes should call services rather than hiding core business rules inside request handlers.
Keep files and modules easy to navigate. A single 1,000-line module may feel fast at first, but it becomes difficult to review and unsafe to change. A maintainable structure keeps related code together while avoiding oversized files.
A maintainable Python project should make the main execution paths obvious. Web applications usually have entry points such as main.py, app.py, or framework-specific modules. Background workers may have a jobs/ or workers/ folder. Shared domain logic should sit below those entry points rather than being duplicated across handlers.
Configuration deserves special attention. A clean project has a single place where environment variables are read, validated, and converted into typed settings. That approach reduces repeated calls to os.getenv and prevents runtime surprises caused by missing or misspelled variables.
from dataclasses import dataclassimport os @dataclass(frozen=True)class Settings: database_url: str log_level: str = "INFO" def load_settings() -> Settings: database_url = os.environ.get("DATABASE_URL") if not database_url: raise RuntimeError("DATABASE_URL is required") return Settings(database_url=database_url)Project structure also affects onboarding. A repository with README.md, pyproject.toml, src/, tests/, and a small docs/ folder tells a new developer where to start. A repository with loose scripts, duplicate config files, and unclear imports forces a new developer to learn by trial and error.
Handle Errors And Testing More Carefully

Reliable Python code handles expected failures explicitly and tests the behavior that matters to users. Error handling and testing are connected because a good test should prove not only the happy path but also the failure path.
Better Error Handling And Exceptions
Good error handling avoids both silence and noise. Catch the exceptions you can handle, add useful context, and let unexpected failures surface where monitoring can catch them. Avoid broad except Exception blocks that hide real defects.
class PaymentProviderError(RuntimeError): pass def charge_customer(payment_client, customer_id: str, amount_cents: int) -> str: try: result = payment_client.charge(customer_id, amount_cents) except TimeoutError as exc: raise PaymentProviderError("Payment provider timed out") from exc return result.transaction_idCustom exceptions help callers decide what to do next. A timeout may be retried. A validation error should be shown to the user. A permission error should be logged and blocked. Treating every error the same way creates confusing behavior.
The official Python errors and exceptions tutorial shows the core exception model: code can catch specific exceptions, raise new exceptions, and preserve the original traceback with exception chaining. In production code, exception chaining is useful because the caller sees a domain-specific error while logs still preserve the technical cause.
A common mistake is catching an exception too early. If a low-level function logs an error, swallows it, and returns None, the caller may continue with invalid data. Let low-level functions raise meaningful exceptions, then handle those exceptions at a boundary that can make a user-facing decision.
def parse_retry_count(raw_value: str) -> int: try: retry_count = int(raw_value) except ValueError as exc: raise ValueError("RETRY_COUNT must be an integer") from exc if retry_count < 0: raise ValueError("RETRY_COUNT must not be negative") return retry_countLogging should add context without exposing secrets. Include entity identifiers such as request IDs, job IDs, or customer account IDs when they help debugging. Avoid logging API tokens, passwords, personal data, or full payment payloads. Good logs make incidents shorter; careless logs create security and privacy risk.
Unit And Integration Testing That Teams Can Trust
Unit tests check isolated logic. Integration tests check boundaries such as databases, APIs, queues, or file systems. A healthy Python project uses both because many bugs appear where modules meet.
def test_get_paid_invoice_rows_filters_unpaid_rows(): rows = [InvoiceRow(amount_paid=100), InvoiceRow(amount_paid=0)] paid_rows = get_paid_invoice_rows(rows) assert len(paid_rows) == 1 assert paid_rows[0].amount_paid == 100Tests should describe behavior, not implementation trivia. A test named test_user_can_reset_password_with_valid_token is more useful than test_reset_function. Clear test names double as documentation for future maintainers.
Coverage numbers help, but they are not the goal. The better question is whether tests cover the business rules, edge cases, integrations, and failure modes that would hurt users if broken.
The pytest documentation is a practical starting point for Python teams because pytest supports readable assertions, fixtures, parametrized tests, and integration-friendly workflows. A team can start with a small test suite and grow it into a reliable safety net.
Trustworthy tests usually have three traits. They test observable behavior, use realistic inputs, and fail for a reason the developer can understand. Tests that depend on ordering, wall-clock time, external networks, or shared local state should be isolated with fixtures, fakes, or test containers where appropriate.
import pytest @pytest.mark.parametrize( ("subtotal_cents", "discount_percent", "expected_total"), [(10000, 10, 9000), (2500, 0, 2500), (999, 100, 0)],)def test_calculate_discounted_total(subtotal_cents, discount_percent, expected_total): assert calculate_discounted_total(subtotal_cents, discount_percent) == expected_totalIntegration tests should cover the boundaries most likely to break in production: database migrations, third-party API contracts, authentication flows, background jobs, file uploads, and scheduled tasks. A small number of high-value integration tests can prevent expensive regressions that unit tests cannot see.
Teams should also decide what must happen when a bug reaches production. A good regression workflow starts by writing a failing test that reproduces the bug, fixing the implementation, and keeping the test in the suite. That habit turns incidents into permanent quality improvements.
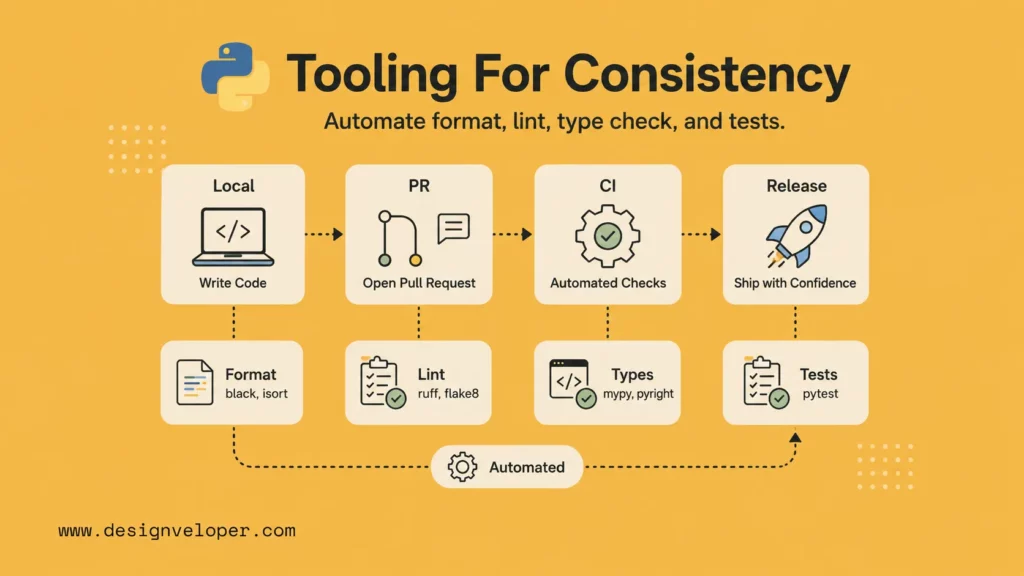
Tooling turns best practices into repeatable checks. Developers should not spend review time arguing about import order, spacing, unused variables, or obvious type mistakes. Let tools catch those issues before pull requests.
| Quality area | Tooling option | What it catches |
|---|---|---|
| Code formatting | Ruff formatter or Black | Consistent layout and low-noise diffs. |
| Linting | Ruff linter documentation | Unused imports, common bugs, style issues, and many Flake8-style rules. |
| Type checking | mypy documentation or Pyright | Type mismatches, optional values, and interface mistakes. |
| Dependency and environment management | pyproject.toml, virtual environments, pip-tools, Poetry, uv, or similar tools |
Repeatable installs and clearer dependency ownership. |
Ruff is especially useful for modern Python teams because it combines fast linting with broad rule coverage. The tool choice matters less than the habit: format, lint, and type-check locally and in CI before review.
[tool.ruff]
line-length = 100
[tool.ruff.lint]
select = [“E”, “F”, “I”, “B”, “UP”]
[tool.mypy]
python_version = “3.12” warn_unused_ignores = true strict_optional = true
Start with a manageable ruleset. Turning on every strict rule in an older codebase can create too much noise. Add rules gradually, fix the highest-risk issues first, and prevent new violations from entering the codebase.
A strong tooling setup usually has three layers. The local layer runs in a developer’s editor or pre-commit hook. The pull request layer runs in CI before review. The release layer runs tests and security checks before deployment. The same commands should run in each layer so developers are not surprised by CI failures.
Pre-commit hooks are useful when a team wants fast feedback before code reaches a pull request. Hooks can format files, lint imports, reject secrets, and block large accidental files. CI should still run the same checks because local hooks can be skipped.
repos: - repo: https: rev: v0.8.0 hooks: - id: ruff args: [--fix] - id: ruff-format - repo: https: rev: v1.13.0 hooks: - id: mypyDependency management is another part of code quality. Pin direct dependencies where stability matters, separate runtime dependencies from development dependencies, and update libraries on a planned cadence. Security scanners and dependency review tools should be part of the workflow for applications that handle customer data.
Type checking should start at module boundaries. Public service functions, API schemas, data transfer objects, and repository interfaces benefit from clear types because those boundaries are where misunderstandings become bugs. Older codebases can adopt typing gradually by enforcing stricter rules on new modules first.
Python Project Structure Best Practices
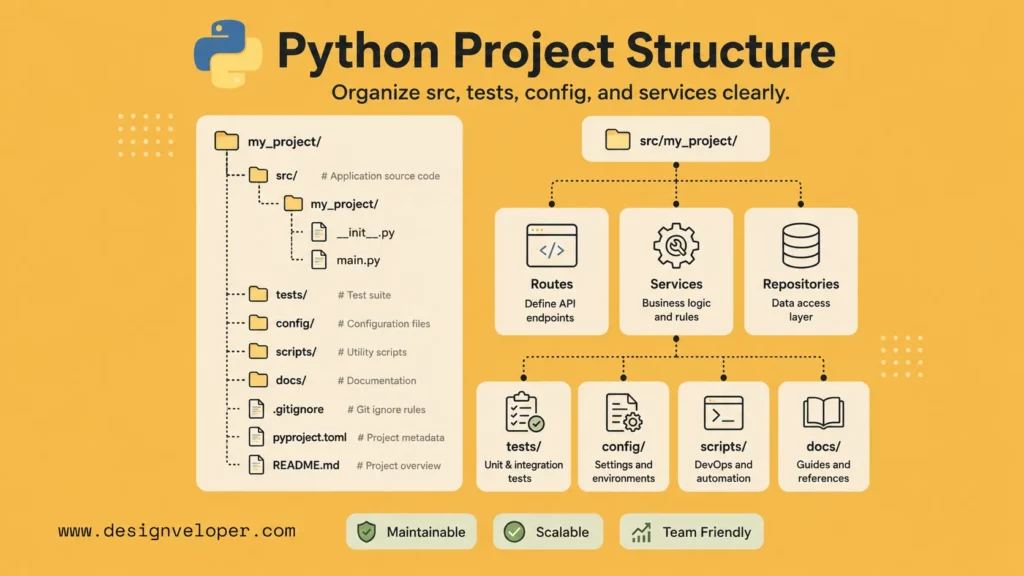
Python project structure best practices make the project easy to run, test, package, and review. Structure is not only about folders; it is about making ownership and boundaries visible.
- Keep src, tests, and config organized: Put importable code under a clear package, tests under
tests/, and configuration in predictable files or environment-based settings. - Make the project easy to run, test, and review: Document setup in
README.md, provide one command for tests, and keep local development close to CI. - Use a layout that supports long-term collaboration: Separate APIs, services, repositories, schemas, jobs, and utilities when the application grows.
A practical review rule is simple: a new developer should be able to clone the repository, install dependencies, run tests, and understand the top-level folders within the first hour. If that is difficult, the project structure is already creating maintenance cost.
For web applications, separate framework glue from business logic. A FastAPI route should validate request input and call a service. The service should hold business rules. Database access should live behind a repository or query layer when the project grows. This separation makes unit tests and future framework changes easier.
A clean project layout should support the way the team works. If the team ships APIs, workers, and scheduled jobs from one repository, the structure should make each runtime visible. If the team publishes a package, the structure should make packaging and imports reliable. If the team builds internal automation, the structure should make configuration and execution commands obvious.
| Project type | Recommended structure focus | Common risk to avoid |
|---|---|---|
| FastAPI or Django application | Keep routes, services, schemas, repositories, and settings separated. | Putting business rules directly inside route handlers or views. |
| AI or data pipeline | Separate data loading, model calls, evaluation, prompts, and persistence. | Mixing experiments, production jobs, and credentials in one script. |
| Reusable Python package | Use clear package metadata, tests, documentation, and a deliberate import layout. | Relying on imports that only work from the project root. |
| Internal automation tool | Provide a predictable CLI, config file, and logging behavior. | Creating one-off scripts that nobody else can safely rerun. |
The tests/ folder should mirror important behavior rather than every internal file. For example, tests for invoice rules can live under tests/unit/billing/, while database and payment-provider tests can live under tests/integration/. A mirrored structure helps developers find tests quickly without forcing an artificial one-test-file-per-module rule.
Repository documentation should include setup commands, required environment variables, test commands, formatting commands, and deployment notes. Documentation does not need to be long. A clear README.md with copyable commands often beats a large wiki page that nobody updates.
install: python -m pip install -e ".[dev]" format: ruff format src tests lint: ruff check src tests mypy src test: pytest testsStructure should evolve with the product. A small proof of concept may start with fewer folders, but production code should gain clearer boundaries before the team adds more features. Refactoring structure early is cheaper than untangling imports after the project has several services, scheduled jobs, and external integrations.
Common Python Habits That Hurt Code Quality

Some Python habits feel productive in the moment but create maintenance debt. The most common pattern is writing code that solves today’s task while hiding tomorrow’s debugging cost.
| Habit | Why it hurts | Better practice |
|---|---|---|
| Clever code instead of clear code | Reviewers spend time decoding intent. | Prefer obvious control flow and clear names. |
| Too much logic in one file or function | Changes become risky and tests become broad. | Split business rules into focused services or functions. |
| Skipping tests, linting, and refactoring for too long | Small issues become release blockers. | Run quality checks in CI and refactor as part of feature work. |
Another harmful habit is mixing configuration, secrets, and business logic. API keys should live in environment variables or secret managers. Feature flags and settings should be explicit. Business logic should not depend on a developer’s local machine state.
Python also makes it easy to mutate shared objects accidentally. Be careful with mutable defaults, shared global state, and functions that change input data in place without making that behavior obvious.
Mutable default arguments are a classic Python pitfall. A default list or dictionary is created once when the function is defined, not each time the function is called. Use None as the default and create a new object inside the function.
def add_tag(tag, tags=[]): tags.append(tag) return tags def add_tag(tag, tags=None): tags = [] if tags is None else tags tags.append(tag) return tagsAnother harmful habit is treating notebooks or exploratory scripts as production systems. Jupyter notebooks are excellent for exploration, but production workflows need versioned modules, tests, logging, retry behavior, and repeatable execution. Move stable logic from notebooks into importable Python modules before other systems depend on it.
Global state also becomes dangerous as a project grows. A module-level client, cache, or configuration object can make tests order-dependent and deployments harder to reason about. Prefer dependency injection for components such as database sessions, payment clients, AI model clients, and message queues when behavior must be tested or swapped.
Finally, avoid delaying refactoring until every feature is finished. Refactoring is safest when it is small, covered by tests, and connected to active work. A team that regularly improves names, boundaries, and tests will usually move faster than a team that waits for a large cleanup project.
Turning Python Best Practices Into A Better Development Workflow
Python best practices are not just style rules. Their real value comes from making projects easier to debug, review, maintain, and scale over time. The workflow should make good habits automatic.
A practical workflow starts with a pull request template, automated checks, and clear review expectations. Every PR should answer what changed, how it was tested, and what risk remains. CI should run formatting, linting, tests, and type checks before a reviewer spends time on the code.
At Designveloper, we treat Python maintainability as product engineering work. Clean Python code matters because backend services, AI features, data workflows, and automation systems often live for years. Our web application development services and AI development services focus on code that teams can operate, monitor, and improve after launch.
A useful team checklist looks like this:
- Format and lint automatically before code review.
- Write tests for changed behavior and important failure paths.
- Keep modules small enough to review in one sitting.
- Document setup, environment variables, and release steps.
- Refactor when code becomes hard to explain, not only when it breaks.
A better workflow turns quality into a sequence that every change follows. Before writing code, clarify the behavior and edge cases. During implementation, keep the change small enough to review. Before review, run formatters, linters, type checks, and tests. During review, focus on correctness, maintainability, and product risk rather than style disputes that tools can settle.
- Start with acceptance criteria: Define the expected behavior, failure modes, and user-visible outcome before implementation begins.
- Design the smallest useful boundary: Choose where the function, service, module, or API contract should live.
- Write or update tests: Cover the happy path, important edge cases, and at least one meaningful failure path.
- Run automated checks: Format, lint, type-check, and test locally before opening the pull request.
- Review for future maintenance: Ask whether a teammate can safely change the code later without hidden context.
For a production team, a pull request checklist might include these questions:
- Does the change have a clear owner and a clear reason?
- Are new modules named after domain concepts rather than technical convenience?
- Do tests cover the business behavior that could break later?
- Are errors handled at the right boundary with useful context?
- Can the code run in CI, staging, and production with the same configuration model?
Python best practices also matter for AI and automation projects. An AI feature often combines prompt templates, retrieval logic, third-party model calls, evaluation data, and product code. Without clear structure, a model change can break user workflows silently. With clear modules, tests, and evaluation checks, the team can improve model behavior while protecting the product experience.
For Python consulting or dedicated product teams, maintainability should be discussed before the first sprint. Architecture decisions such as package layout, API boundaries, test strategy, and observability determine whether the project remains easy to extend after launch. That is why engineering partners should be evaluated not only on delivery speed but also on how they protect code quality over time.
The best long-term signal is boring reliability: new developers can onboard, CI failures are understandable, tests catch real regressions, production logs contain useful context, and refactoring is normal work. When those signals are present, Python best practices have become part of the development culture rather than a document nobody reads.
FAQs About Python Best Practices

Should Python Teams Always Follow PEP 8?
Python teams should follow PEP 8 as a default because it improves readability and consistency. Teams can make local exceptions when a different convention clearly improves clarity, but exceptions should be intentional and documented.
What Tools Help Enforce Python Best Practices?
Common tools include Ruff for linting and formatting, Black for formatting, mypy or Pyright for type checking, pytest for tests, pre-commit for local hooks, and CI pipelines for repeatable checks before merge.
How Do You Keep Python Code Maintainable Over Time?
Keep Python code maintainable by using clear names, small functions, consistent structure, automated tests, linting, type checks, documented setup, and regular refactoring. The team should also review architecture and ownership as the project grows.


{kind=link}