
batchLLM
As the name implies, batchLLM is designed to run prompts over multiple targets. More specifically, you can run a prompt over a column in a data frame and get a data frame in return with a new column of responses. This can be a handy way of incorporating LLMs in an R workflow for tasks such as sentiment analysis, classification, and labeling or tagging.
It also logs batches and metadata, lets you compare results from different LLMs side by side, and has built-in delays for API rate limiting.
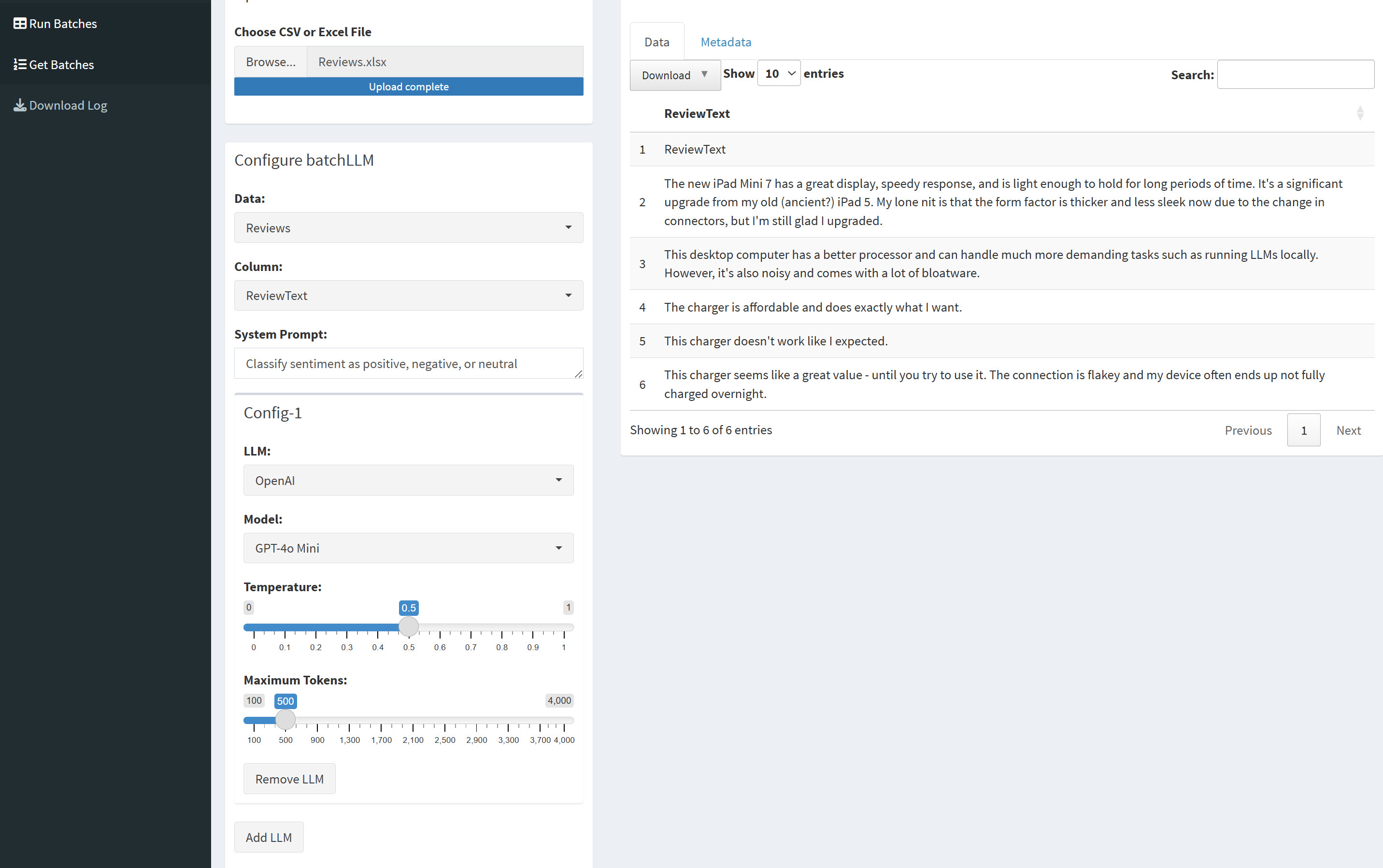
batchLLM’s Shiny app offers a handy graphical user interface for running LLM queries and commands on a column of data.
batchLLM also includes a built-in Shiny app that gives you a handy web interface for doing all this work. You can launch the web app with batchLLM_shiny() or as an RStudio add-in, if you use RStudio. There’s also a web demo of the app.
batchLLM’s creator, Dylan Pieper, said he created the package due to the need to categorize “thousands of unique offense descriptions in court data.” However, note that this “batch processing” tool does not use the less expensive, time-delayed LLM calls offered by some model providers. Pieper explained on GitHub that “most of the services didn’t offer it or the API packages didn’t support it” at the time he wrote batchLLM. He also noted that he had preferred real-time responses to asynchronous ones.
We’ve looked at three top tools for integrating large language models into R scripts and programs. Now let’s look at a couple more tools that focus on specific tasks when using LLMs within R: retrieving information from large amounts of data, and scripting common prompting tasks.
ragnar (RAG for R)
RAG, or retrieval augmented generation, is one of the most useful applications for LLMs. Instead of relying on an LLM’s internal knowledge or directing it to search the web, the LLM generates its response based only on specific information you’ve given it. InfoWorld’s Smart Answers feature is an example of a RAG application, answering tech questions based solely on articles published by InfoWorld and its sister sites.
A RAG process typically involves splitting documents into chunks, using models to generate embeddings for each chunk, embedding a user’s query, and then finding the most relevant text chunks for that query based on calculating which chunks’ embeddings are closest to the query’s. The relevant text chunks are then sent to an LLM along with the original question, and the model answers based on that provided context. This makes it practical to answer questions using many documents as potential sources without having to stuff all the content of those documents into the query.
There are numerous RAG packages and tools for Python and JavaScript, but not many in R beyond generating embeddings. However, the ragnar package, currently very much under development, aims to offer “a complete solution with sensible defaults, while still giving the knowledgeable user precise control over all the steps.”
Those steps either do or will include document processing, chunking, embedding, storage (defaulting to DuckDB), retrieval (based on both embedding similarity search and text search), a technique called re-ranking to improve search results, and prompt generation.
If you’re an R user and interested in RAG, keep an eye on ragnar.
tidyprompt
Serious LLM users will likely want to code certain tasks more than once. Examples include generating structured output, calling functions, or forcing the LLM to respond in a specific way (such as chain-of-thought).
The idea behind the tidyprompt package is to offer “building blocks” to construct prompts and handle LLM output, and then chain those blocks together using conventional R pipes.
tidyprompt “should be seen as a tool which can be used to enhance the functionality of LLMs beyond what APIs natively offer,” according to the package documentation, with functions such as answer_as_json(), answer_as_text(), and answer_using_tools().
A prompt can be as simple as
library(tidyprompt)
"Is London the capital of France?" |>
answer_as_boolean() |>
send_prompt(llm_provider_groq(parameters = list(model = "llama3-70b-8192") ))
which in this case returns FALSE. (Note that I had first stored my Groq API key in an R environment variable, as would be the case for any cloud LLM provider.) For a more detailed example, check out the Sentiment analysis in R with a LLM and ‘tidyprompt’ vignette on GitHub.
There are also more complex pipelines using functions such as llm_feedback() to check if an LLM response meets certain conditions and user_verify() to make it possible for a human to check an LLM response.
You can create your own tidyprompt prompt wraps with the prompt_wrap() function.
The tidyprompt package supports OpenAI, Google Gemini, Ollama, Groq, Grok, XAI, and OpenRouter (not Anthropic directly, but Claude models are available on OpenRouter). It was created by Luka Koning and Tjark Van de Merwe.
The bottom line
The generative AI ecosystem for R is not as robust as Python’s, and that’s unlikely to change. However, in the past year, there’s been a lot of progress in creating tools for key tasks programmers might want to do with LLMs in R. If R is your language of choice and you’re interested in working with large language models either locally or via APIs, it’s worth giving some of these options a try.


{kind=link}