")
Vector databases are an important component of many AI applications these days. They empower AI to perform AI and LLMs to perform various tasks, from information retrieval and product recommendations to visual search and anomaly detection. The databases address the limitations of traditional databases in handling unstructured data, as well as provide LLMs with long-term memory and up-to-date information.
Vector databases come into two main types: open-source and proprietary. Which one should you choose for your AI project? What are the best open-source vector databases to consider? This blog post will give you a detailed comparison of these open-source databases. But first, let us clarify what “open-source” means.

What Are Open-Source Vector Databases?
Open-source vector databases are where you can store vector embeddings, and their source code is publicly available to use and modify. They have enough necessary capabilities of a vector database:
- They are designed to perform similarity search using distance metrics. These databases are different from traditional relational counterparts, which organize structured data in columns and rows for exact keyword matches. They store vectors (numerical values of unstructured data converted using embedding neural networks), no matter what your original data is (e.g., text or images).
- Using different indexing techniques and optimized algorithms (e.g., IVF, HNSW, or PQ/IVFQ), these databases calculate the distances between the stored embeddings and a query vector to find “nearest neighbors” (most relevant items). As these embeddings contain the meaning and relationships in data points, vector databases can return contextually similar results even when they use synonyms or paraphrases.
- Open-source vector databases allow for scalability when your datasets increase to millions or billions of vectors. They have that ability by offering built-in sharding, clustering, horizontal scaling, distributed indexing, and efficient storage & compression techniques.
- Vector databases don’t work alone. They integrate with a range of AI tools and models (e.g., LangChain, CLIP) to automatically create embeddings or rerank search results. This integration makes them a crucial component in a complex AI system.
Beyond these inherent capabilities, open-source databases offer publicly free sources of code under an open-source license, normally Apache 2.0 or MIT. They allow you to tailor or extend their code to meet your specific needs. Besides, you can run them everywhere without vendor lock-in and contribute back to the community by debugging or adding new features.
Which One Should You Choose Between Open-Source Vs Proprietary Vector Databases?
Open-source and proprietary vector databases have their own strengths and best use cases. To consider which to choose, you first need to understand the main differences between the two types of vector databases:
| Factor | Open-Source | Proprietary |
| Control & Customization | Full access to the code. In other words, you can use, modify, and share the code for commercial applications without cost or restrictive licensing. | No or limited access to the code. This means you often have no rights to modify the code and need to rely on the provider’s APIs and updates. |
| Ease of Installation & Maintenance | You handle setup, deployment, monitoring, backups, and scaling yourself. | Providers manage the underlying infrastructure, allowing you to install and maintain databases easily. |
| Compliance & Security | You take responsibility for meeting security and compliance requirements. | Providers offer built-in security certifications and measures to secure your data privacy and ensure compliance. |
| Vendor Lock-In | Low. You can migrate your data easily. | High. Migrating to other vector databases may require extra complex steps. |
| Typical Examples | ChromaDB, Qdrant, Milvus | Pinecone |
Once you’ve understood the key differences between open-source and proprietary vector databases, you should consider your project’s requirements to identify which one fits best.
Open-source options are ideal if:
- You want full control of code and data
- Your team can handle the underlying infrastructure and associated tasks (e.g., deployment or scaling) and prioritize customization.
- You have a tight budget, or want to avoid ongoing license fees.
Closed-source databases are better if:
- Your team wants a managed service with minimal operations and can trade off some flexibility for quicker time-to-market.
- You require compliance certifications, strong SLAs, and dedicated support from providers.
Top 10 Open-Source Vector Databases
So, what are the best open-source vector databases you should consider? Let’s take a look at our curated list below:
1. Chroma
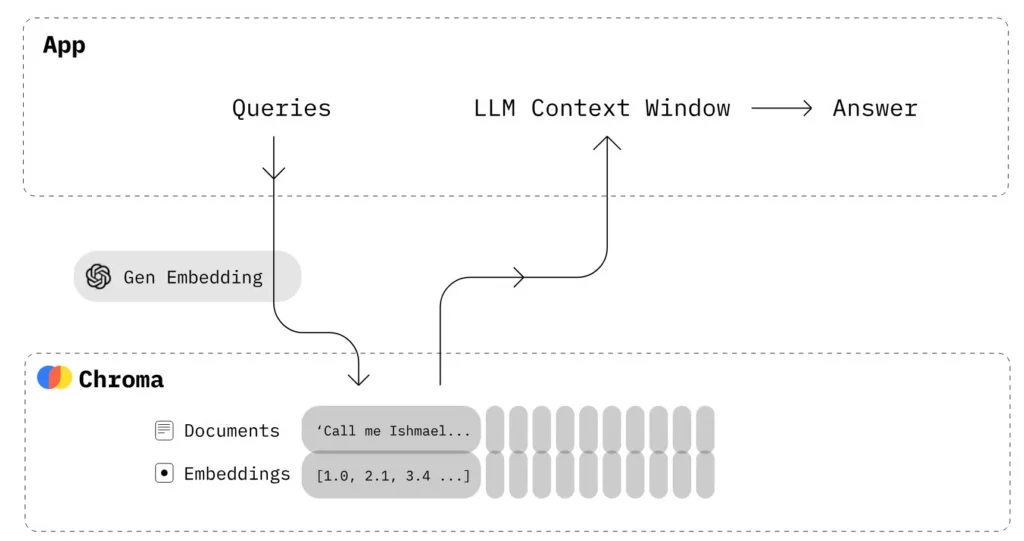
ChromaDB is a lightweight vector database developed by a San Francisco-based startup. It’s open-source and works under the Apache 2.0 license for commercial use. This database aims to store and search for numerical vectors to pinpoint information relevant to a user query.
It hosts various embedding models to automatically convert any data types to vectors. Beyond vector embeddings, ChromaDB also stores its original data and corresponding metadata (e.g., unique IDs).
When a user query comes, ChromaDB also transforms it into embeddings using the same embedding model and mostly uses HNSW (Hierarchical Navigable Small World) indexing to implement ANN (Approximate Nearest Neighbor) search. By calculating distances between the stored embeddings and the query vector, ChromaDB can extract semantically relevant information.
Key features:
- ChromaDB offers different deployment options. Accordingly, you can perform similarity searches on single servers. Or you can install it on a virtual machine in managed cloud services (like AWS, Azure, or Google Cloud Platform) to implement complex RAG workflows. If you don’t want to manage a server yourself, install the database in the Chroma Cloud. This fully managed hosting option covers maintenance and scaling on your behalf.
- ChromaDB is developer-friendly and supports integration with various embedding models (OpenAI, Hugging Face) and AI tools (LangChain, LlamaIndex, etc.). You can also work with ChromaDB on various programming languages (e.g., Python, JavaScript, Ruby, or Go).
- ChromaDB uses Rust-based high-performing storage and Apache Arrow to read and find vectors more easily.
- ChromaDB keeps data in object storage (e.g., Amazon S3 or Google Cloud Storage) and automatically migrates data between storage tiers based on its usage frequency. This tiering reduces costs while keeping similarity search fast.
2. Milvus
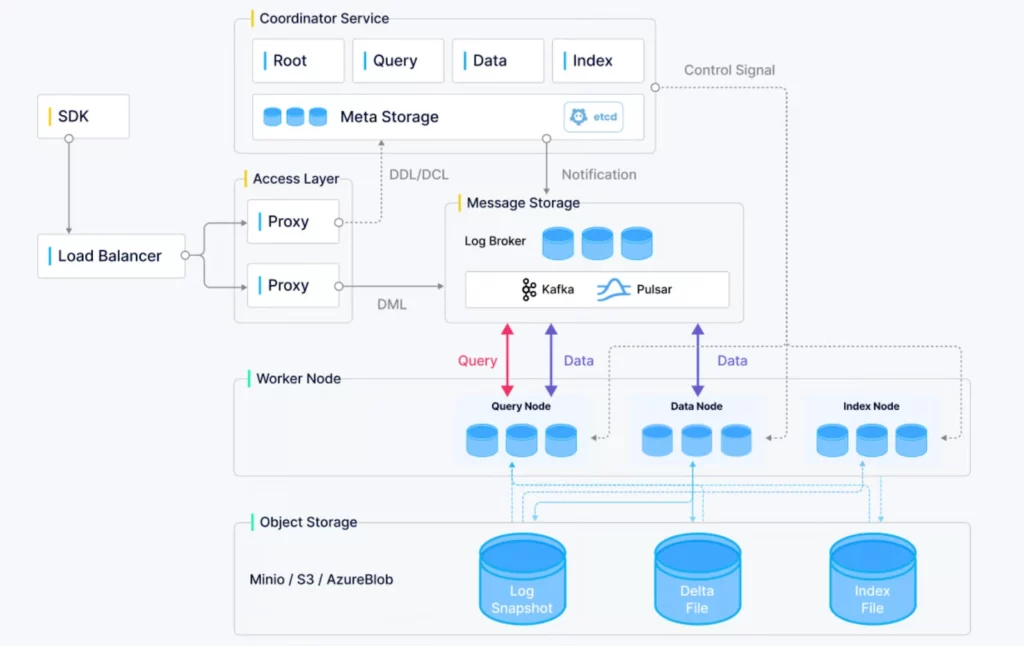
Developed by Zilliz, Milvus is an open-source vector database with the largest GitHub forks and GitHub stars in 2025. It operates efficiently across multiple environments, including a single machine and large-scale distributed systems. Beyond its open-source version under the Apache 2.0 license, Milvus also comes with a managed, cloud-native service.
Milvus provides three deployment options for different data scales. They include Milvus Lite, Milvus Standalone, and Milvus Cluster.
- Milvus Lite is a lightweight version written in Python and easily integrated into your application. It works best for fast prototyping in Jupyter Notebooks or with edge devices with limited resources.
- Milvus Standalone is often deployed on a single server. All its components are packaged into a single Docker container for convenient deployment.
- Milvus Distributed is deployed on Kubernetes clusters. This deployment option features a cloud-native architecture that can scale horizontally to process up to billions of vectors.
Key features:
- Milvus provides data modeling capabilities that help you organize unstructured and multimodal data into structured formats. With Milvus, you can store any data types, including vector embeddings and structured attributes (e.g., titles, timestamps, and categories).
- Milvus is high-speed because it’s optimized to perform well in various hardware architectures (e.g., AVX512, SIMD, or GPUs). Further, it offers a variety of in-memory and on-disk search algorithms (e.g., HNSW, IVF, and DiskANN).
- A single Milvus cluster can serve various separate tenants concurrently and isolate data in different levels (database, collection, partition/partition-key). These isolation methods enable multiple tenants to share the same cluster and perform fast searches.
- Milvus’s cloud-native and highly decoupled system architecture enables seamless scalability. This architecture helps the database perform search, data insertion, and indexing effectively.
- Milvus supports a wide range of search types, including ANN Search, Filtering Search, Range Search, and even Full-Text Search.
3. Weaviate
Weaviate is an open-source vector database that comes with built-in vector/hybrid search, hosted machine learning models, and security measures. These features help developers build, iterate, and scale AI applications effectively, regardless of their technical skills.
Beyond an open-source database, Weaviate also combines other tools and services (including Weaviate Cloud, Agents, Embeddings, and third-party models) to create a seamless ecosystem for searching and AI agent building.
The database offers multiple deployment options. They include Weaviate Cloud (for diverse use cases from evaluation to production), Docker (for local evaluation and development), Kubernetes (for development and production), and Embedded Weaviate (for basic, fast evaluation).
Key features:
- Weaviate supports searches using both semantic similarity and exact keywords. It also offers powerful filtering options (e.g., ACORN and Sweeping) to find the nearest vector embeddings to a query vector that also match specific conditions.
- Weaviate has a billion-scale architecture that can adapt to any workload and seamlessly integrate with various embedding and reranking models to handle text and multimodal data.
- Weaviate can scale horizontally and operate on a range of nodes in a cluster using built-in sharding and replication.
- The database offers the Backup feature that integrates natively with common cloud services (e.g., AWS S3, Azure Storage, or GCS). This functionality allows you to back up an entire instance or just selected collections.
- Weaviate has built-in multi-tenancy capabilities to isolate data within a cluster for different customer groups or projects and for fast, efficient querying.
- Weaviate provides various data compression methods to balance system performance and resource costs. These methods include Product Quantization (PQ), Binary Quantization (BQ), Scalar Quantization (SQ), and Rotational Quantization (RQ).
4. FAISS
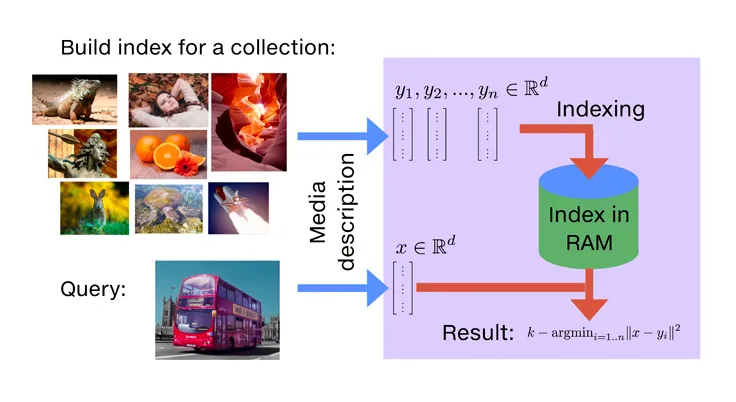
Faiss (Facebook AI Similarity Search) is an open-source library Meta AI created to implement similarity searches. Although FAISS isn’t a full vector database, it’s still a high-speed indexing and searching tool that many developers use to find approximate nearest neighbors (ANN) to a query vector and speed up GPU performance.
However, it doesn’t have built-in database-level capabilities, like data management, backups, or metadata filtering. Besides, FAISS runs on one computer (CPU or GPU) by default. So if your data is bigger than a single machine’s processing capability, FAISS can’t automatically distribute datasets and search tasks to other machines.
Key features:
- FAISS comes with indexing choices, including Inverted File Index (IVF), Graph-Based Index (HNSW, NSG), and Locality-Sensitive Hashing (LSH) (e.g., flat or hierarchical). Beyond ANN search methods, FAISS also supports Flat Index (brute-force search) to look for exact matches if needed.
- FAISS provides a wide range of data compression methods to store vectors efficiently. These methods, like Binary & Scalar Quantization, Product Quantization, or Neural Quantization, reduce vector size for less space usage and quicker distance measures.
- FAISS can process millions or even billions of vectors efficiently and allow for scalability, but on a single server.
- You can work with FAISS through Python and C++.
- FAISS offers the key capabilities (e.g., creating and training indexes, performing searches, and supporting GPU) for Python through the
faissPython package. So, use Python if you want to implement fast prototyping, machine learning, or data science projects. - Meanwhile, C++ is ideal if you need low-latency production systems, direct integration with the C++ backend, or custom Faiss extensions (e.g., tailored index types or algorithm modifications).
- FAISS offers the key capabilities (e.g., creating and training indexes, performing searches, and supporting GPU) for Python through the
5. Qdrant
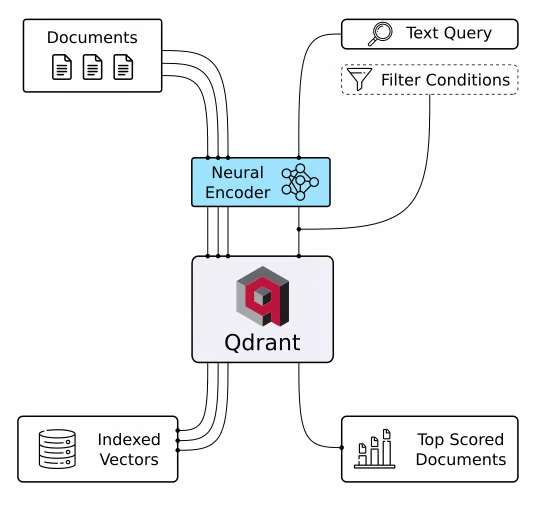
Qdrant is a high-performance, highly scalable vector database that handles high-dimensional vectors for large-scale AI systems. The database can run under the Apache 2.0 license or be self-hosted on the Qdrant Cloud.
It can scale beyond a single server (“node”) and be optimized for billion-scale performance, fault tolerance, and high vector availability. The database is developed in Rust for high speed and reliability, even when handling billions of vectors.
Key features:
- Qdrant performs multiple searches, including semantic search for vectors, hybrid search for text, multimodal search, and single-stage filtering. For similarity search, it uses a proprietary modification of the HNSW algorithm, along with different distance metrics (cosine, Euclidean, Manhattan, and dot product), to estimate the relevancy of vectors precisely. The database also stores additional information with vectors (e.g., string matching, numerical ranges, or geolocations) to narrow down the search space.
- Qdrant comes with built-in multi-tenancy capabilities. The database divides a single collection for efficient data isolation, retrieval, and privacy.
- Qdrant supports advanced compression methods, like Product, Scalar, and unique Binary Quantization. These methods reduce memory usage and enhance search performance among high-dimensional vectors.
- Qdrant integrates with various leading embedding models and frameworks, like txtai, LangChain, and Haystack.
6. Vespa
Vespa is an open-source AI search platform operating under the Apache 2.0 license. Although it’s naturally not a full vector database, yet comes with vector search capabilities, ML-based ranking, and real-time inference for various use cases, like RAG or product recommendation.
Beyond vector embeddings, the platform also stores and searches other data types, including structured data, text, and tensors (multi-dimensional arrays). Vespa can scale seamlessly with billions of constantly evolving data items and handle thousands of queries with very low latency (< 100 milliseconds).
Key features for vector search:
- Vespa supports exact nearest neighbor search and ANN search using a modified version of HNSW indexing. Accordingly, Vespa’s enhanced HNSW algorithm allows you to combine a nearest-neighbor search with query filters, index multi-vector documents, and implement full CRUD (Create, Update, or Delete) operations in real-time. Further, each content node keeps one HNSW graph per tensor field, which lets a query search only one graph on that node.
- Vespa uses techniques like PCA (Principal Component Analysis) to shorten vectors by identifying and removing less-informative dimensions. Further, it allows you to choose an accurate way to store each numerical value in a vector, including Int8, bfloat16, float, and double. Lower accuracy options (like Int8 with 8 bits per number) require less memory and save much cost, but come with less precise searches.
- Vespa supports embedding models from Hugging Face, BERT, ColBERT, and SPLADE.
- Vespa features phased reranking to return the most relevant results based on querying.
7. Pgvector
Pgvector is not a full vector database, but an open-source extension of PostgreSQL for vector similarity search. This extension makes PostgreSQL a powerful, high-performance database that can store and search for vector embeddings.
It’s released under the PostgreSQL License, so you can freely use, customize, and distribute its code for commercial use, without cost. You can work with any programming language that PostgreSQL supports, like Python, Go, or Java.
Key features:
- Pgvector comes with vector database capabilities. It allows PostgreSQL to store vector embeddings in different formats (e.g., sparse, binary, float32, or float16) alongside normal data types (e.g., text or numbers). The extension, accordingly, performs exact or approximate nearest neighbor searches and uses different distance metrics (e.g., Euclidean, inner product, or cosine) to measure similarity.
- Pgvector supports two indexing techniques: HNSW and IVFFlat. HNSW (Hierarchical Navigable Small World) organizes vectors in a graph-based structure, while IVFFlat splits vector embeddings into lists and performs searches through a subset of the lists most relevant to a query vector.
8. OpenSearch
OpenSearch is an open-source platform released under the Apache 2.0 license. It acts as a comprehensive data search and analytics tool, but you can consider it a vector database because it provides powerful capabilities to store, index, and find vector embeddings using similarity search.
Key features:
- OpenSearch offers built-in indexing capabilities for semantic, hybrid, and multimodal searches.
- The platform provides local and external machine learning models to embed the raw data. Accordingly, you can choose pre-trained models (e.g., Sentence Transformers or Hugging Face’s Cross Encoders), upload your custom model for specific use cases, or integrate with external models.
- OpenSearch 3.0 allows for GPU deployment to increase performance for large-scale vector workloads, speed up index creation by 9.3x, and reduce operational costs. Further, this latest version reduces storage usage by one-third by eliminating unnecessary vector data sources and prioritizing primary data.
- OpenSearch 3.0 integrates the Apache Calcite query builder into its SQL and PPL. This integration helps users create and fine-tune queries more intuitively and facilitates tasks, like security analysis or log exploration.
- OpenSearch 3.0 divides the work of indexing (writing) and finding (reading) data into isolated resources or servers. This speeds up searches, even when heavy indexing takes place.
9. Valkey
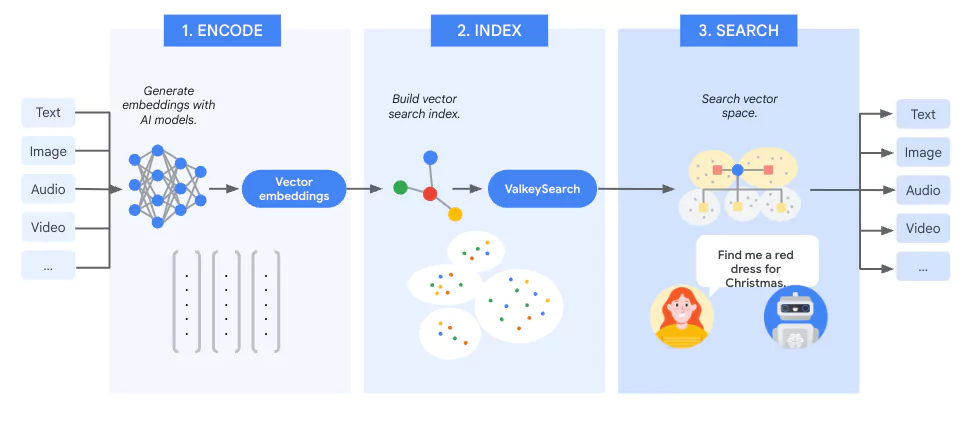
Valkey is an open-source project backed by the Linux Foundation. It can function as a standalone database (for simple use cases) or work in mission-critical systems, with built-in replication and high availability.
Valkey introduces valkey-search, an official module enabling similarity search capabilities. This functionality helps you build indexes and search through billions of vectors kept inside your Valkey instances. Valkey-search proves useful in various real-time applications, including personalized recommendations, conversational AI, multimodal search, and fraud detection.
Key features of valkey-search:
- Released under the BSD-3-Clause license, valkey-search mostly performs a semantic search to identify similar embeddings with the K-Nearest Neighbor (KNN) algorithm and distance metrics (L2, IP, or cosine). It improves the traditional HNSW algorithm to speed up searches and reduce resource usage.
- This module isn’t limited to semantic searches, but extends to hybrid querying. It combines KNN searches with additional metadata, which is represented in numeric or tag formats. When implementing hybrid queries, valkey-search automatically chooses one of the strategies to execute querying: Pre-filtering and Inline-filtering.
- Valkey-search offers different scaling options: horizontal, vertical, and replicas.
- Valkey-search comes with a point-in-time RDB snapshotting mechanism to maintain zero downtime, high vector availability, and minimal operational overhead.
- This module stores its entire search index in memory to accelerate vector lookups and updates.
- Valkey-search runs on a multi-threaded architecture to distribute the workload across CPU cores. It also integrates special synchronization techniques to let threads work concurrently. So, when you add more CPU cores, the system can scale almost linearly.
10. Apache Cassandra

Apache Cassandra is an open-source NoSQL database that can manage large data volumes. Its 5.0 version allows for vector search by using storage-attached indexing (SAI) and dense indexing methods to find exact or approximate nearest neighbors in a high-dimensional vector space.
SAI is a highly scalable feature that offers unparalleled I/O (Input/Output) throughput by adding column-level indexes to the columns of any vector data type. This feature uses the JVector algorithm (which works in a similar way to HNSW) to perform ANN search.
Cassandra also uses CQL (a typed language) to support a diversity of data types, from native types and user-defined types to collection types. Besides, the database integrates with embedding models (e.g., Word2Vec, Meta LLaMA 2, or CLIP) to transform text documents and images.
Comparison Of Top Open-Source Vector Databases
Below is a comparison table summarizing all the key features of the best open-source vector databases we discussed above:
| Database | Open-source License | Scalability/Distributed Support | Search Features/Index Types | Real-time/CRUD/Updates | Main Use Cases |
| Chroma | Apache 2.0 | Good for small to medium-sized systems | Similarity search + metadata filtering, with simple indexing | Support vector insertion and updates; but heavier operations can be slower due to its local nature | Prototyping LLM retrieval, small/medium RAG, quick local development, apps where data privacy and offline development are crucial |
| Milvus | Apache 2.0 | Scale to multiple nodes | Supports hybrid searches with various indexing techniques | Support real-time ingestion, updates, deletes | Large-scale production for vector/multimodal search, recommendation systems, etc. |
| Weaviate | BSD-3-Clause | Scale horizontally, sharding, multi-node, etc. | Semantic/hybrid searches using HNSW | Enable real-time updates | Semantic search, knowledge graphs, hybrid search, apps requiring built-in modules |
| FAISS | MIT | Vertical scaling | Mainly ANN searches using diverse index types | Must combine with other tools to build a full CRUD feature | Image retrieval, NLP, recommendation systems, etc. |
| Qdrant | Apache 2.0 | Support clustering, sharding, etc. | Mainly HNSW; semantic search + metadata filtering | Support real-time insertions, updates, deletes | Advanced search, recommendation systems, RAG, data analysis & anomaly detection, AI agents |
| Vespa | Apache 2.0 | Support large, ever-evolving data, multiple nodes, etc. | Support exact & approximate nearest neighbor searches; modified HNSW | Full CRUD | Hybrid search, RAG, personalized recommendation, semi-structured navigation |
| Pgvector | PostgreSQL License | Depend on PostgreSQL’s scalability | HNSW & IVFFlat indexing; support exact or approximate nearest neighbor searches | Inherit CRUD semantics from PostgreSQL | Semantic search, image & multimedia similarity search, AI customer support, data classification |
| OpenSearch | Apache 2.0 | Support distributed systems, shards, replicas, etc. | Semantic, hybrid, and multimodal searches | Support insertion, updates | Trace analytics, log analytics, Amazon S3 log analytics, metrics ingestion |
| Valkey | BSD 3-Clause | Enables vertical, horizontal, and replicas scalability | KNN & enhanced HNSW; semantic/hybrid searches | Natively support CRUD operations | Personalized recommendations, fraud detection, conversational AI, visual search, semantic search |
| Apache Cassandra | Apache 2.0 | Distribute data across multiple nodes and enable parallel processing | Use JVector for ANN searches, storage-attached indexing (SAI) & dense indexing | Support CRUD through its query language (Cassandra Query Language) | NLP, recommendation systems, image recognition, fraud detection, IoT & sensor data search |
Conclusion
Through this blog post, Designveloper has given you the best open-source vector databases to consider in 2025. Each comes with strengths and fits different use cases. Consider your project’s requirements and choose the right databases to build a high-quality, scalable AI system for your business.
In case you’re looking for a trusted, experienced partner in developing such systems, Designveloper is a good option!
With 12 years of operations in software and AI development, our team has completed 200+ successful projects for clients across industries, from finance and healthcare to education and construction. We have mastery of cutting-edge technologies, like LangChain, combined with embedding models, vector databases, and other tools, to create custom, scalable AI solutions.
Our projects span from a conversational bot that provides personalized recommendations and automates customer support tasks to a medical assistant that captures health signals and automatically sends them to the healthcare staff’s devices.
With our proven Agile approaches and dedication to excellence, we commit to on-time and within-budget delivery. Our deliverables and strong technical capabilities also receive good customer reviews with the 4.9 Clutch rating. If you want to transform your existing software with AI integration, contact us! Designveloper is eager to help!


{kind=link}