")
RAG, short for Retrieval-Augmented Generation, is a technique that empowers an LLM-powered application by retrieving up-to-date, relevant information from external data sources, instead of relying only on the LLM’s training knowledge base. Without RAG, LLM systems may generate irrelevant, outdated, or incorrect responses because they work heavily on static datasets that have a cut-off date. RAG has been a trendy topic among the developer community these days due to its transformative benefits. If you are curious about how to build an RAG application from scratch, this guide is the right place to start. Keep reading and explore what you need in RAG app development.
Simple RAG System Components
There are many RAG architectures that consist of various components to serve different purposes, from answering open-ended questions to performing multi-turn conversations. In the first session, we want to focus on a simple RAG system to help you understand how it basically works.
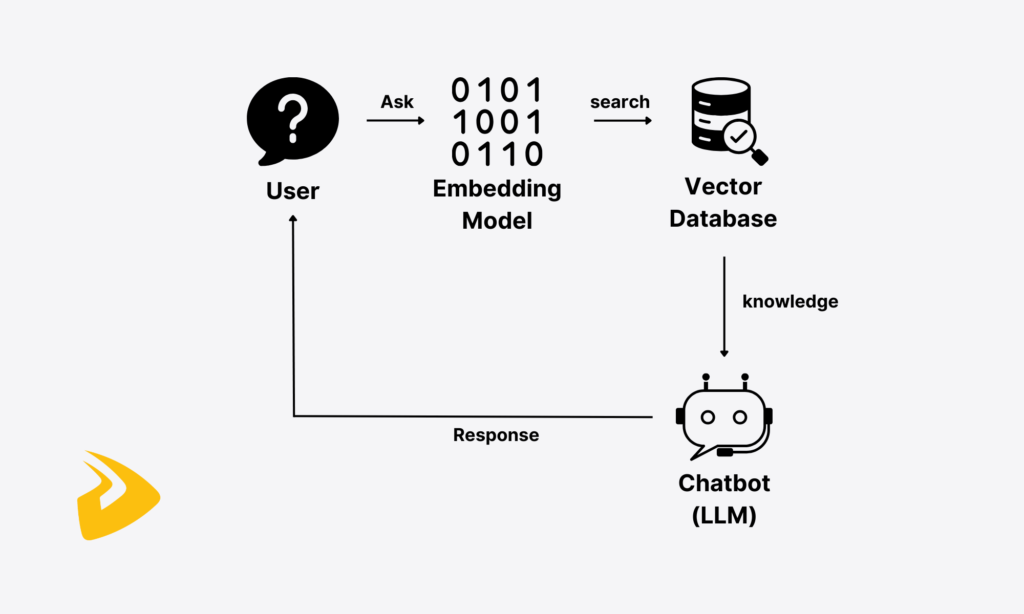
The simple RAG application often covers the following components:
- Embedding Model: This system aims to convert a user’s input query and information from external documents into embeddings, which are vector representations or numeric vectors. Today’s popular embedding models come from trusted providers like Ollama, OpenAI, Google Gemini, or Fireworks. These models are important because machines and large language models can’t understand natural language text. Instead, they can only read and interpret data in numeric formats. That’s why embedding models are essential to help LLMs understand both the retrieved data and the input.
- Vector Database: The embeddings transformed from external documents are stored in vector stores for similarity search and retrieval later. Some common vector databases include Milvus, Chroma, FAISS, and Pinecone.
- Chatbot: Chatbot, in this case, is an LLM model that takes over the generation part. The LLM receives and fuses the retrieved information, along with a user’s query, into a prompt. Then, it’ll generate a contextually relevant, factually accurate, and personalized response.
How to Build a RAG System from Scratch?

Now, let’s take a closer look at how to develop a simple RAG system from scratch:
Step 1. Setting Up Your Development Environment
Before building a RAG application, you need to prepare a robust development environment to ensure your project will run smoothly, remain easy to maintain, and avoid unexpected conflicts when it scales up.
Required Tools and Libraries
You need the following necessary tools and libraries before diving into code. Meanwhile, ollama is an open-source platform that runs LLMs locally on your computers:
- Python 3.9+: the main programming language to code a RAG system. You can check to see whether this version or higher is installed with the command line: python3 –version. If not, you can install the latest version from python.org.
- Virtual environment tool:
venv(built-in) orcondato separate dependencies.
- LangChain & LangChain-Community: LangChain is a powerful, open-source framework that chains various components to simplify RAG app development. Meanwhile, LangChain-Community contains connectors, loaders, models, and embeddings maintained by the community. Both are required in this guide.
- FAISS: an efficient vector store for similarity search. You can choose other vector databases depending on your needs, like Milvus, Weaviate, or Pinecone.
- Ollama: an embedding model that runs LLMs locally on your devices without the need to access a cloud service or an external server. We also use a chat model (e.g.,
llama3.1) and an embedding model (e.g.,nomic-embed-text). You can choosesentence-transformersor OpenAI if you prefer cloud embeddings.
- Utilities: e.g.,
dotenv(for secure management of API keys),uvicorn(for running APIs),beautifulsoup4(for parsing HTML text),pydantic(for data validation).
Installing System Tools
First, open your Terminal on macOS by searching in the Spotlight Search and start installing ollama:
brew install ollama# or:curl -fsSL https://ollama.com/install.sh | shRun Ollama in the background. Please make sure that this command line will run all the times. Otherwise, embeddings and chat will fail:
ollama serveDownload models:
ollama pull llama3.1 # chat modelollama pull nomic-embed-text # embedding modelSetting Up a Virtual Environment
Creating and activating a virtual environment is a crucial step to isolating your RAG system’s dependencies from other projects and making them easier to manage.
python3 -m venv rag_envsource rag_env/bin/activate # On Mac/Linux# orrag_env\Scripts\activate # On WindowsInstalling Python dependencies
Then, you’ll install all the dependencies we mentioned above. These dependencies are necessary to build a RAG system:
pip install langchain langchain-community langchain-core langchain-text-splitterspip install faiss-cpu beautifulsoup4 fastapi uvicorn python-dotenv pydanticOrganizing Your Project Structure
Next, you need a clean structure to help your project stay clear and efficient when it scales. Here’s a suggestion to organize your project structure:
rag-system/
│── rag_env/ # Virtual environment
│── app/
│ ├── __init__.py
│ ├── main.py # FastAPI entry point
│ ├── ingestion/ # Data ingestion scripts
│ ├── retriever/ # Vector DB & retrieval logic
│ ├── llm/ # LLM and LangChain pipeline
│ ├── api/ # API routes
│── .env # API keys & secrets
│── requirements.txt # Dependencies
│── README.md # Project documentation
- main.py: runs your FastAPI app
- ingestion/: processes and stores documents in your vector DB.
- retriever/: retrieves relevant documents for queries.
- llm/: integrates the LLM and LangChain pipeline.
- api/: defines REST endpoints for your RAG system.
Step 2. Data Preparation
If you want your RAG system to generate context-aware, accurate responses, you need a trusted and solid knowledge base. That knowledge base must contain up-to-date, relevant, and clean data so that the LLM can understand and perform well on it. That’s why data preparation is a crucial step in the RAG pipeline. It involves collecting, cleaning, and formatting data, creating a knowledge base, and indexing data.
Collecting Data
You can connect any external data sources to the RAG pipeline, as long as they meet the two following criteria: 1) those sources must align with the system’s needs, and 2) those sources must contain verified, up-to-date, and unbiased information. For example, if your RAG app aims to handle customer support, your data should cover FAQs, troubleshooting documentation, and user guides. Accordingly, these data sources can be:
- Public sources: often include government databases, academic papers, websites, etc.
- Internal sources: often involve your company’s internal documents like meeting notes, policy manuals, etc.
- Databases: consist of CRM systems, customer service logs, product catalogs, etc.
Cleaning and Formatting Data
Raw data often contains noise, inconsistencies, and irrelevant information. So, cleaning and standardizing the raw data is essential to ensure the LLM won’t fuse messy data into its response. This often involves removing duplicates, handling missing values, removing irrelevant information, and ensuring consistent data formats (e.g., text fields, dates, or numerical values).
Open-source frameworks like LangChain offer document loaders (e.g., WebBaseLoader or pandas to perform light data prep tasks. These document loaders help collect and transform raw data into a usable form known as Document objects. The framework doesn’t integrate tools to handle heavy cleaning and formatting, like deduplicating or removing noisy data. Therefore, in production-ready projects, data prep like collection, cleaning, and formatting needs to be implemented in a separate ETL (Extract, Transform, Load) pipeline. This allows you to create a clean, ready-to-use dataset that is integrated into the RAG pipeline later.
In this guide, to avoid complexity and confusion, we assume that the external data source doesn’t require much cleaning. Therefore, we’ll use document loaders to ingest data from external data sources and format it in a standardized Document object format. We also leverage BeautifulSoup to filter out noise (e.g., menus or footers) and only keep useful HTML parts (e.g., title, header, and content)
import bs4from langchain_community.document_loaders import WebBaseLoader# Keep only relevant parts of the HTMLbs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))loader = WebBaseLoader( web_paths=("https://www.designveloper.com/blog/what-is-langchain/",), bs_kwargs={"parse_only": bs4_strainer},)docs = loader.load()print(f"Loaded {len(docs)} doc(s). First 300 chars:\n")print(docs[0].page_content[:300])Chunking
The raw text is now loaded and lightly cleaned. But large documents often overwhelm the LLM as they may exceed the token limits (“context window”) of the model. Even when the documents fit the model’s window, it struggles to search for information in very long documents. Therefore, splitting them into management chunks helps the model handle the information more effectively by matching queries against more focused sections.
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=150)chunks = text_splitter.split_documents(docs)print(f"Created {len(chunks)} chunks")Embedding & Indexing
After splitting, an embedding model is used to convert each chunk into a numerical vector. This process is known as “vector indexing.” The vectors are stored in a vector store, like FAISS, Chroma, or Milvus.
from langchain_community.embeddings import OllamaEmbeddingsfrom langchain_community.vectorstores import FAISSembeddings = OllamaEmbeddings(model="nomic-embed-text")vectorstore = FAISS.from_documents(chunks, embedding=embeddings)# (Optional) Save to disk for reusevectorstore.save_local("faiss_index")# To load back later:# vectorstore = FAISS.load_local("faiss_index", embeddings)Apart from vector indexing, there are other indexing techniques, like inverted indexing or hybrid indexing. Inverted indexing refers to searching for exact keywords in certain documents. Meanwhile, hybrid indexing combines different indexing techniques for fast retrieval and high relevance. If you work in LangChain, the bad news is that the framework doesn’t directly support inverted and hybrid indexing. These techniques are only accessed through LangChain’s third-party integrations, like Elasticsearch or Redis.
Step 3. Coding the RAG System
Now, let’s gather all the components above! The full code below will show all the steps to build a RAG system: Loading → Chunking → Indexing → Retrieval → Generation
3.1. Import external libraries, modules, and functions into your code.
# --- Imports ---import bs4from langchain_community.document_loaders import WebBaseLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_community.embeddings import OllamaEmbeddingsfrom langchain_community.vectorstores import FAISSfrom langchain_community.chat_models import ChatOllamafrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthrough2. Load the dataset (web page) and keep only title/headers/content
# Only keep post title, headers, and content from the full HTMLbs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))loader = WebBaseLoader( web_paths=("https://www.designveloper.com/blog/what-is-langchain/",), bs_kwargs={"parse_only": bs4_strainer},)docs = loader.load()print(f"Loaded {len(docs)} document(s); first 400 chars:\n")print(docs[0].page_content[:400])3. Chunk the text (helps retrieval & LLM context limits)
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, # adjust for your docs chunk_overlap=150 # small overlap keeps context continuity)chunks = text_splitter.split_documents(docs)print(f"Created {len(chunks)} chunks")4. Implement the vector database (FAISS) with local embeddings
# Local embedding model served by Ollamaembeddings = OllamaEmbeddings(model="nomic-embed-text")# Build a FAISS index from chunksvectorstore = FAISS.from_documents(chunks, embedding=embeddings)# (Optional) persist to disk for reuse:# vectorstore.save_local("faiss_index_langchain_blog")5. Implement the retrieval function
# Turn the vectorstore into a retriever (top-k=4 by default)retriever = vectorstore.as_retriever(search_kwargs={"k": 4})def format_docs(docs): # Join retrieved chunks into a single context block return "\n\n".join(d.page_content for d in docs)6. Generate answers with a local chat model (Ollama)
# Local chat modelllm = ChatOllama(model="llama3.1", temperature=0.2)# A compact RAG promptprompt = ChatPromptTemplate.from_template( """You are a helpful assistant for question answering.Use the provided context to answer. If the answer isn't in the context, say you don't know.Keep the answer under 5 sentences.Question:{question}Context:{context}Answer:""")# Compose a RAG chain: (question) -> retrieve -> format -> prompt -> llm -> textrag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())7. Put it all together & test
def ask(question: str): answer = rag_chain.invoke(question) # Also show sources (URLs) for transparency sources = { d.metadata.get("source") for d in retriever.get_relevant_documents(question) if d.metadata.get("source") } return answer, list(sources)Step 4. Testing and Deployment Considerations
Testing, Evaluation, and Debugging
Once your RAG application is developed, the next step is to check whether it works as planned. This phase is crucial because retrieval systems and large language models (LLMs) themselves are non-deterministic. Particularly, the indexing method and search parameters used in RAG can affect what you extract. Meanwhile, LLMs may generate different answers even with the same prompt, because these models are probabilistic. So if you don’t evaluate and monitor the quality of retrieval and LLM outputs, you risk offering irrelevant content or incorrect but convincing answers – that’s often known as “hallucinations.”
Some testing methods for traditional software development can be adopted to test the technical aspects and usability of the RAG app. They include unit testing, performance testing, security testing, and more. Further, you can use prompt injection testing to check whether your app is vulnerable to malicious prompts.
Deployment Considerations
Now, your testing is done, and the next step is to deploy it to real users. So, here’s what you need to do for a successful deployment:
1. Packaging the System: Use FastAPI or Flask to serve your chatbot as an API.
2. Infrastructure choices: Decide whether you want your app to be deployed locally or on cloud platforms. Local deployment is suitable for testing and small teams, while cloud deployment is good for scalability.
3. Performance optimization: To optimize the RAG system’s performance, you can select smaller embedding models to enable faster retrieval, cache frequent queries to save compute resources, and choose scalable vector databases.
4. Monitoring: Continuously track your RAG system’s latency, evaluate retrieval accuracy, and collect user feedback to improve its performance.
Challenges to Watch Out For When Building RAG

RAG is expected to reach $165 billion in 2034 in its global value, reflecting the high expectations to feed real-time data into LLM-generated responses. Along with the trend is the increasing investment of companies in RAG system building. But developing a RAG system sounds simple, as in fact, there are various challenges to watch for:
Data Ingestion and Chunk Quality
RAG will connect external data sources to LLMs to help them extract the most relevant up-to-date data. But what if the data is incorrect and irrelevant? The generated response definitely contains wrong information. That’s why choosing external data sources, data pre-processing methods, and indexing techniques affects the quality of data fed into the LLM’s response.
Chunking is also a big problem. As mentioned above, chunking refers to splitting long documents into smaller pieces of text to help LLMs read and interpret all the information effectively. However, if chunks are too large, they can dilute the information, while too small chunks can lose the context and hinder the model from understanding the full meaning. Besides, too much chunk overlap can slow down the RAG system’s performance. That’s why careful data pre-processing and chunking are crucial to maintain data accuracy and relevance.
Retrieval Precision vs Recall
The next problem involves retrieval. In RAG, retrieval precision refers to how many retrieved chunks are relevant, while recall measures how many of the truly relevant chunks are successfully fetched. Although we want both metrics to be high. But there is often a trade-off between them. Let’s take this example to better understand why:
Imagine you ask, “What are the health benefits of coffee?”
- If the system retrieves 2 chunks and overlooks other irrelevant content, it means the retrieval precision is high. But the problem here is that it may miss other useful details, like “reduce Parkinson’s” or “improve mood.” This means low recall.
- If the system retrieves 10 chunks, including some about coffee and others about the comparison between coffee and other drinks, the retrieval recall is high. But the LLM may struggle to navigate through irrelevant data. This means precision is low.
Obviously, if you focus too much on precision, your answers risk being incomplete. But if you focus too much on recall, your responses risk being noisy and even misleading. So, to reduce this conflict in practice, developers need to combine various methods, like re-ranking, hybrid search, or confidence thresholds. Re-ranking helps prioritize results by pushing the most relevant ones to the top. Hybrid search combines semantic and keyword searches. Meanwhile, confidence thresholds help filter out irrelevant chunks.
Hallucinations and Context Accuracy
Integrating RAG into LLMs doesn’t mean that we completely resolve hallucinations. Even with strong retrieval, LLMs still make up answers. This happens for many reasons. First, if the retriever extracts low-quality or partially relevant information, the LLM may try to guess missing information and fill in the gaps. Second, if the context window of the LLM is too small to hold all necessary data, the model might use incomplete evidence to produce its reasoning. And finally, if the scoring or ranking of irrelevant documents is mistakenly pushed to the top, the LLM still fabricates answers.
One of the most effective ways to address this problem is to apply LLM guardrails. These are mechanisms used to evaluate LLM-generated responses, as well as ensure accuracy and compliance. Dashdoor, an online platform that allows independent contractors (“Dashers”) to pick up orders from local restaurants or stores and deliver them to customers, integrated these mechanisms into its RAG chatbots. This successfully cut down potentially compliance issues by 99% and overall hallucinations by 90%.
System Robustness and Maintenance
RAG systems are not static because they depend on many components, like data sources, chat models, vector databases, and retrievers. If any of these components change or even when user needs evolve, but the systems are not monitored continuously, the retrieval quality will drop accordingly. That’s why it’s crucial to perform regular evaluation, monitoring, and maintenance to keep the system reliable and efficient.
Enhancing Your RAG System

If you want to improve your RAG system and resolve the challenges we mentioned above, here are several techniques you can adopt. These techniques enhance the accuracy of retrieved data, the quality of generated responses, as well as the system’s scalability when your data evolves.
Using Metadata and Self-Query Retrievers for Precision
One of the common problems in RAG applications is that they fetch too much irrelevant information. That’s why adding metadata filters to your vector database can reduce noise. This metadata includes various attributes, like author, document type, or timestamps. It allows you to categorize documents intelligently and helps the system search for the relevant information more effectively.
Metadata is also a part of self-query retrievers. This technique allows the RAG system to automatically analyze a user’s query to identify which parts of the query need metadata-based or semantic similarity search. Accordingly, the system can intelligently apply metadata filters to narrow down the set of candidate documents and then run a similarity search only in that filtered set. For this reason, your RAG system can enhance retrieval precision or accuracy.
Hybrid Search, Re-ranking, and Quality Improvements
Not all RAG models use DPR (Dense Passage Retrieval) to search for information based on semantic meaning. Some still leverage traditional keyword search called BM25 to find exact keywords, if tasks are simple and keyword-based. By combining these two retrieval methods, the system can capture both exact keyword matches and semantic meaning. This is particularly helpful in legal or technical documents where specific terms are important.
Re-ranking is also a good way to improve retrieval quality. After extracting a candidate set of documents, a smaller transformer will be used to arrange them by relevance before sending them to the LLM. This extra step allows the model to work on the most accurate context, hence improving response quality. Apart from these two methods, you can adopt other strategies to enhance the retrieval quality, like intelligent chunking, prompt engineering, or feedback loops.
Scalability and Evaluation Strategies
When your RAG system scales up, you have to confront scalability challenges. In this case, large datasets can slow down retrieval while increasing costs. To address this problem, you should consider:
- caching frequent queries to mitigate redundant computation
- distributing embeddings to different vector databases, like Milvus or Pinecone to process large-scale indexing
- performing incremental updates instead of re-indexing the entire dataset.
Besides, adopt techniques like RAGAS Score and RAG Triad for effective RAG evaluation. RAGAS Score offers an array of metrics to measure the RAG system’s retrieval, generation, and how these two work together. Some metrics include Faithfulness, Answer Relevancy, Context Precision, and Context Recall. Meanwhile, RAG Triad focuses on evaluating the context relevance, groundedness, and answer relevance of the system.
How Designveloper Helps You Build a RAG System

This article gave you a detailed guide to building a RAG system step by step. In case you need expert help with technical things, Designveloper will be a good partner!
Designveloper is one of the leading software development and IT consulting companies in Vietnam. We have extensive technical skills with 50+ modern technologies to successfully deploy high-quality, scalable AI solutions that connect to your internal data sources securely. We also invest in emerging tools like LangChain, AutoGen, or CrewAI to create conversational bots that flexibly generate contextual responses grounded in your up-to-date, verified data. Using RAG, we integrate different features to power our conversational bots, from memory for multi-turn conversations to API connectivity for real-time data retrieval.
Our AI solutions help clients attract target customers and receive positive feedback. For example, we developed a product catalog-based advisory chatbot. Integrated into the client’s website in the form of bubble chat, the conversational bot can offer specific product information based on a user’s query, suggest the right products for the user’s needs, and auto-send confirmation emails.
With more than 200 successful projects and proven AI frameworks (SCRUM, Kanban), we’re confident in delivering timely projects within budget. Contact us now and receive a detailed consultation on your RAG project.


{kind=link}
Your blog is a treasure trove of knowledge! I’m constantly amazed by the depth of your insights and the clarity of your writing. Keep up the phenomenal work!
Your blog is a shining example of excellence in content creation. I’m continually impressed by the depth of your knowledge and the clarity of your writing. Thank you for all that you do.
Your blog is a true hidden gem on the internet. Your thoughtful analysis and in-depth commentary set you apart from the crowd. Keep up the excellent work!