
Chatbots have long been our assistants across industries, like healthcare, finance, and manufacturing. They answer questions about different topics, from technical details to internal policies. From rule-based to LLM-powered chatbots, we’ve witnessed a long-term evolution of these conversational assistants. And now, technologies advance, and RAG (Retrieval-Augmented Generation) is integrated to ground LLM chatbots in evidence-backed information instead of only relying on guessing as before. So, how can you build a RAG chatbot? This article offers detailed steps to navigate this process seamlessly.
What Is a RAG Chatbot?

A RAG chatbot is an intelligent conversational bot that retrieves up-to-date, contextually relevant information to generate appropriate responses to a user’s query. This assistant can access external databases (e.g., your company’s internal policy manuals, FAQs, or guidelines) and adapt to new information to answer domain-specific questions and handle specialized issues.
Meanwhile, traditional chatbots work mainly based on predefined rules or pre-training data. These traditional assistants often base their responses on historical or generic data, which may be incorrect or irrelevant to a user’s query.
For example, if you ask, “What is the refund policy of Company X?”, a traditional customer support chatbot may respond based on the general or outdated data instead of accessing Company X’s web pages and finding the company’s exact refund information. But a RAG-powered chatbot has that ability. This makes it a valuable tool in areas where information accuracy and relevance are prioritized, like customer service, medical diagnosis, or legal advisory.
The Benefits of RAG Chatbots
RAG chatbots will reach an estimated value of $11 billion in 2030 due to their various transformative benefits.
The first advantage of these assistants is increased accuracy and relevance. RAG focuses on two key processes: retrieval and generation. This technique allows LLM-powered chatbots to ingest and fetch the most relevant information from external sources. This makes the chatbots provide context-aware, accurate answers, hence increasing user experience while improving efficiency.
Further, RAG enables real-time data updates. Traditional chatbots often depend on training data, which can be obsolete and general to perform specific tasks. But RAG allows your chatbots to proactively adapt to constant data updates in knowledge bases without the need for retraining. This makes them useful in domains where up-to-date information is crucial, like customer service, news delivery, or finance.
Another visible benefit is that RAG chatbots can handle domain-specific tasks more effectively than traditional LLMs. It’s not because the former is trained on specialized expertise, but is capable of approaching and using domain-specific knowledge to answer complex questions about healthcare, legal services, or any technical domains.
Grounding answers in factual, relevant information also keeps businesses compliant. If regulatory policies evolve, but chatbots still base their responses on outdated information, they can put your company a risk of violating these regulations.
Finally, RAG reduces hallucinations, a common problem in LLMs. When encountering a query that they don’t have enough evidence to back up, LLMs don’t often say, “Sorry, I don’t know.” Instead, they intend to find plausible information to fill the gaps and fabricate responses. But with RAG, LLMs can extract and feed more reliable, relevant information into their answers, hence mitigating the likelihood of making up responses.
RAG ChatBot Examples
All those benefits make RAG chatbots widely adopted across industries, typically:
- Customer Support Chatbot: This RAG chatbot pulls information from a company’s FAQs, knowledge base, product catalogs, and other relevant sources to answer a user’s question about certain products or services. For example, when a customer requests, “Show me budget laptops under $500 with good battery life,” the chatbot will extract the information from the retailer’s product database.
- Healthcare Information Assistant: This chatbot fetches verified medical guidelines, research articles, patient health records, and more to provide evidence-backed answers and increase the productivity of healthcare professionals. For example, a hospital chatbot retrieves drug information to answer “What are the side effects of this medicine?”
- Internal Knowledge Assistant: This chatbot helps employees answer questions by extracting from their company’s policy documents, project files, and other relevant sources. For instance, a corporate HR chatbot pulls from internal HR documentation to support onboarding for new hires.
- Legal Research Assistant: This chatbot fetches data from case laws, regulations, and more to accelerate legal research and minimize errors. For instance, a law firm chatbot can extract the latest update on data privacy law in the EU, with citations from verified sources.
- Education & Training Chatbot: This chatbot pulls information from courses, lecture notes, and other online resources to support learning. For instance, a study chatbot can retrieve from online maths resources to answer “Explain the vertex in simple terms and how to determine it.”
Step-by-Step Guide to Building a Chatbot Using the RAG
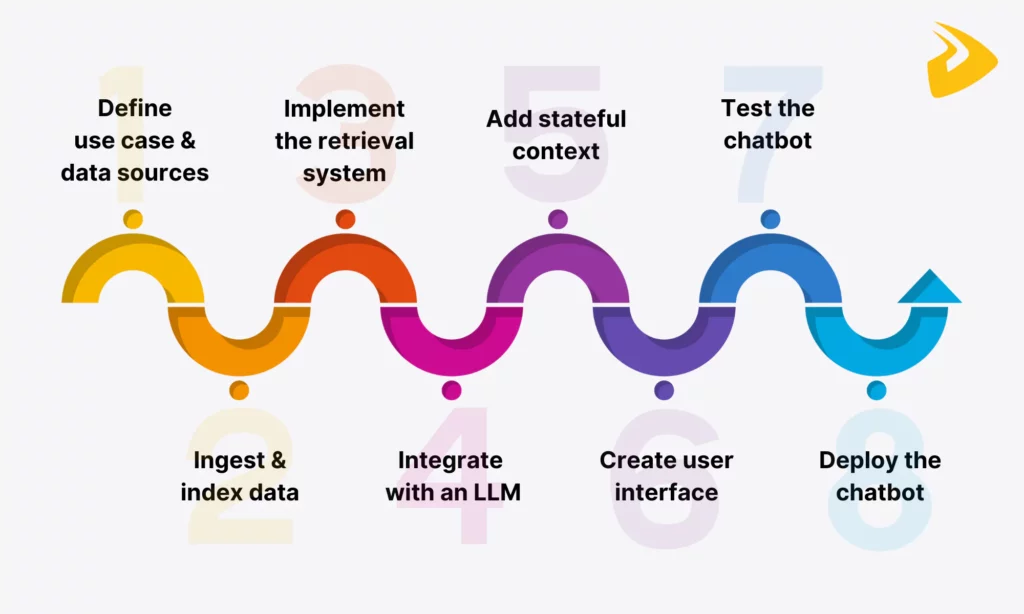
Now, let’s dive into the following eight steps to build a RAG chatbot from scratch!
Step 1. Define Your Use Case & Data Sources
A RAG chatbot works best if it has a well-defined goal and verified, relevant data sources. The first guides you on how to identify your specific use case and prepare the right data sources.
Define specific objectives
Base your chatbot’s ultimate goals on crucial factors, like the bot’s main users, primary tasks (e.g., answering FAQs or summarizing documents), scope of work, tone (e.g., professional or friendly), and other constraints (i.e., about budget, privacy & compliance, or latency). Followed by these factors are well-defined metrics to measure your project’s success. Some success metrics you may consider are answer accuracy (top-k grounded), average response time, resolution/deflection rate, thumbs-up rate, and citation rate.
Identify the right data type and sources
Which data types should your bot read?
- Unstructured data is ideal for explanations, how-tos, policies, and long answers, often found in PDFs, DOCX, manuals, research papers, etc.
- Semi-structured data shines if you need to group answers by headings or sections (e.g., “Troubleshooting → Network Issues”), or filter by tags and fields (e.g., date, author, or category). For example, if a user requests “Only show articles updated after 2024”, semi-structured data should be integrated in this case. This data is often extracted from email templates, logs, JSON help articles, Notion/Confluence pages, etc.
- Structured data is the best fit if you need numeric, factual, or catalog-style answers where precision matters. This data can be extracted from databases, issue trackers, product catalogs, pricing tables, etc.
Once you have determined the right data type and where it lives, consider extracting from ONLY relevant, verified sources that align with the bot’s specific goals. This ensures the later retrieval of the most pertinent information.
Prepare sample data and data sources
Don’t rush into a large-scale project. Instead, start with a pilot one with a representative sample of 50-200 documents that involve the top use cases. These documents should also cover the most common FAQs and edge cases, as well as only contain the latest information.
Step 2. Data Ingestion & Indexing
You’ve defined your use case and data sources. Now, let’s move on to loading, pre-processing, and indexing data to prepare data for building a RAG chatbot.
Clean and normalize data
Data quality will impact the efficiency of retrieval and the accuracy of later responses. So, cleaning and standardizing data is essential to make the data clean and good for your chatbot to consume. Here’s what you can do to pre-process data:
- Remove noise, such as headers, footers, navigation bars, and boilerplate text.
- Deduplicate repeated content that can distort retrieval.
- Maintain consistent encoding by using UTF-8 to avoid errors with special characters.
- Normalize data by converting files into plain text or Markdown.
Tip: After cleaning and standardizing data, you’ll keep the link back to the original source (the URL, file path, or document ID) for citations, but still allow your bot to work with standardized versions.
Create embeddings for data
Embeddings are numeric vectors that contain the semantic meaning of text. These vector representations allow your chatbot to “interpret” and extract relevant information.
The embedding process is done using tools from OpenAI, HuggingFace, and more. For example, OpenAI Embeddings (e.g., text-embedding-ada-002) is considered highly accurate and easy to integrate via APIs, while HuggingFace’s sentence-transformers is open-source and best for local deployment. If you prefer advanced open-source options for domain-specific embeddings, opt for InstructorXL or MTEB-ranked models.
So, how does the embedding process take place? Once you have standardized documents, they’re split into chunks. Then, each chunk goes through an embedding model to get a vector and attach metadata such as source, author, doc_type, or tags.
Store data in a vector database
The generated vectors are then stored in a vector database for quick similarity search. Some common vector stores include Pinecone, FAISS, Weaviate/Qdrant, and Neo4j + Vector Indexing.
To choose the most fitting vector database and let it work best, you should focus on the following things:
- Consider the database size and performance based on your data volume:
- Small-scale (prototyping, <10K documents): Use FAISS locally or lightweight choices like Chroma.
- Medium-scale (10K – 1M documents): Leverage Weaviate or Qdrant.
- Large-scale (enterprise, millions+ documents): Choose Milvus Cloud or Pinecone as they provide distributed indexing, lower operational costs, and horizontal scaling.
- Tips: Don’t forget to estimate your data growth and pick a vector database that allows seamless scalability.
- Store both vectors and metadata for semantic similarity. Metadata makes retrieval more intelligent and effective. For instance, the metadata
sourcehelps the retriever trace back to the original file path or URL, whileupdated_atassists searches within certain periods to filter outdated or irrelevant docs.
- Leverage namespaces or collections to create logical folders for easy retrieval inside the vector DB. A namespace (e.g.,
support_articles,product_specs) helps you separate different data domains clearly. Meanwhile, the collections group chunks into one namespace (e.g.,support_articles/billing). These factors help avoid searches in the wrong docs by restricting searches to one domain, proving very useful for multi-tenant apps.
- Keep versioning to retire outdated information. Accordingly, you can:
- Attach the
versionfield in metadata (e.g.,v1.1,v2.0) - Track
updated_atand filter by the latest date - Keep old versions, but flag them clearly in metadata if your RAG chatbot requires strict compliance with internal policies or regulations.
- Attach the
Step 3. Implement the Retrieval System
Your data is cleaned, embedded, and stored in your chosen vector database. Next, you need to implement the retrieval system by selecting suitable search methods and setting up the retriever in open-source RAG frameworks like LangChain.
Choose the appropriate search method
There are three main search methods: Keyword Search, Semantic Search, and Hybrid Search. Each works best for different use cases:
- Keyword Search: Matches exact words from the query to your documents. It’s ideal for fact-based or structured queries.
- Semantic Search: Compares the embeddings of both the documents and the original query to find text with a similar meaning. It’s useful for conversational queries or natural questions.
- Hybrid Search: Combines both keyword and semantic searches to enhance accuracy. It works best when you need to capture both similar meanings and exact terms.
Tip: You should set semantic search as your chatbot’s default, then layer keyword or hybrid search if your use case requires exact matches (e.g., medical codes or legal citations).
Set up the retriever in LangChain
Using open, composable frameworks like LangChain helps you retrieve the top relevant documents based on user queries. For example, here’s how you can use a vector store retriever in LangChain:
from langchain.vectorstores import FAISSfrom langchain.embeddings import OpenAIEmbeddings# Load embeddingsembeddings = OpenAIEmbeddings(model="text-embedding-ada-002")# Connect to vector store (FAISS here, but Pinecone/Qdrant/Weaviate also work)vectorstore = FAISS.load_local("vector_index", embeddings)# Create retrieverretriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k":5})# Example querydocs = retriever.get_relevant_documents("How do I reset my password?")for d in docs: print(d.page_content, d.metadata)Optimize the retriever’s performance
Consider the following strategies to enhance the performance of your retrieval system:
- Chunking: Too large chunks can involve irrelevant text, while too small chunks lead to context loss. Therefore, identify how many tokens each chunk should contain. Don’t forget to estimate appropriate overlaps to maintain the context and help the retriever understand the text’s meaning. The ideal chunk size varies by use case, but 300-800 tokens with 10-20% overlap are common.
- Reranking: Reranker models (e.g., LangChain’s FlashRank) help you re-prioritize retrieved documents by relevance to narrow down the system’s search.
- Retrieval Parameters Optimization: You should also tell the retriever how many documents to extract (
k) and how strict it should be (similarity threshold). Further, you should test retrieval by querying the vector store with test questions and checking whether the top results actually match the intent. This early test helps you adjust chunking, embedding model, metadata filters, or any component to ensure the best results.
- Speed Considerations: Caching frequent queries for repeated lookups is a good way to accelerate the retrieval speed. Also, use ANN (Approximate Nearest Neighbor) indexes like FAISS, Quadrant, or Weaviate for fast retrieval if your datasets are large.
Step 4. Integrate with an LLM
Now that your retrieval system is established, you need to connect it with an LLM. Your LLM choice depends on various factors, like performance requirements, budget, and privacy needs. LangChain now offers built-in integrations with popular language models, like OpenAI’s GPT models, LLaMA, or Anthropic Claude. You can easily install the models of OpenAI and Claude through your API keys. But if you opt for open-source LLMs like LLaMA, you can integrate them through ChatOllama (langchain-ollama) or the Hugging Face model hub.
Next, you’ll leverage LangChain’s pre-built chains to combine the retriever with a chosen LLM, typically:
- RetrievalQA: Ideal for Q&A style chatbots (e.g., knowledge base bots). This chain retrieves relevant documents, passes them to the LLM, and returns a context-aware response.
- ConversationalRetrievalChain: Works best for chatbots with memory (e.g., customer support assistants). This chain can recall past interactions and keep context throughout multi-turn conversations.
By combining all the essential components, you can automate the entire RAG pipeline, from querying to generating and returning contextually relevant answers with optional citations.
Step 5. Add Stateful Context (Optional but Recommended)
Stateful context refers to the state when a RAG chatbot stores and remembers past user interactions to provide more personalized, context-aware, and relevant responses.
Without a stateful context, users have to repeat themselves, and your chatbot hardly keeps interactions natural and connected. Especially when complex queries arise and require multi-turn conversations to handle, stateless apps fail to keep track of prior exchanges and therefore, struggle to address the problems. That’s why stateful context, albeit optional, should be added when you build a RAG chatbot.
So, how can your RAG chatbot store and retrieve session history for smoother conversations? In LangChain, there are many ways to do that:
In-Memory Storage
This option is ideal for prototypes or short-lived sessions. It temporarily stores history during the chat, which disappears when the session ends.
from langchain.memory import ConversationBufferMemory from langchain.chains import ConversationChain from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-4", temperature=0) memory = ConversationBufferMemory() conversation = ConversationChain(llm=llm, memory=memory) response = conversation.run("Hi, I’m Alex.") print(response) response = conversation.run("What’s my name?") print(response) # Model remembers: "Alex"Database or Long-Term Storage
This is best for applications in which conversations need to continue beyond a single chat session. Databases such as Redis, SQL, or MongoDB help store user interactions keyed by user IDs. LangChain offers integrations to connect with these databases, like RedisChatMessageHistory.
from langchain.memory import ConversationBufferMemoryfrom langchain_community.chat_message_histories import RedisChatMessageHistory history = RedisChatMessageHistory(session_id="user123", url="redis://localhost:6379") memory = ConversationBufferMemory(chat_memory=history) Conversation-Specific Chains
Use LangChain’s pre-built chain, like ConversationalRetrievalChain to merge retrieval with memory. This allows RAG chatbots, especially retrieval-based ones, to both extract relevant documents and recall past information.
from langchain.chains import ConversationalRetrievalChain from langchain.chat_models import ChatOpenAI retriever = vectorstore.as_retriever() llm = ChatOpenAI(model="gpt-4", temperature=0) qa = ConversationalRetrievalChain.from_llm(llm, retriever) chat_history = [] result = qa({"question": "What is LangChain?", "chat_history": chat_history}) chat_history.append(("What is LangChain?", result["answer"])) result = qa({"question": "Who created it?", "chat_history": chat_history}) print(result["answer"]) Step 6. Create a User Interface
Your backend is ready, but your RAG chatbot still needs a good user interface (UI) for users to interact with. Below are some UI tools you may leverage to build a seamless and engaging UI:
- Streamlit: An open-source Python framework for rapid prototyping and demos. It doesn’t require much coding.
- Panel: A Python library for interactive, data-rich applications. It has more customizable layouts than Streamlit.
- Custom React UI: Best for production-grade chatbots. It can be incorporated with LangChain through a backend API (FastAPI/Flask), allowing you to fully control the design and scalability.
Here’s an example of creating a simple user interface with Streamlit:
import streamlit as stfrom langchain.llms import OpenAIfrom langchain.chains import ConversationChainfrom langchain.memory import ConversationBufferMemory# Initialize the LLM and memoryllm = OpenAI(temperature=0)memory = ConversationBufferMemory()conversation = ConversationChain(llm=llm, memory=memory)# Streamlit app layoutst.set_page_config(page_title="LangChain Chatbot", page_icon="🤖")st.title("🤖 LangChain Chatbot")# Chat inputuser_input = st.text_input("You:", "")# Session state for conversation historyif "history" not in st.session_state: st.session_state.history = []if user_input: response = conversation.predict(input=user_input) st.session_state.history.append((user_input, response))# Display conversationfor user_msg, bot_msg in st.session_state.history: st.markdown(f"**You:** {user_msg}") st.markdown(f"**Bot:** {bot_msg}")Step 7. Test Your Chatbot
Now, building is done, and it’s time to test your RAG chatbot. This is a very crucial step to ensure your chatbot will work as expected and deliver a seamless user experience. Here are some testing methods you can adopt before deployment:
- Unit Testing: Verify how each component, especially retrieval and generation, works. Evaluate its accuracy and completeness of extracted documents through metrics like Precision or Recall, while validating the quality and relevance of generated answers.
- Session & Context Testing: Evaluate whether the chatbot remembers past exchanges and keeps track of the chat’s context.
- Stress Testing: Test your chatbot’s limits and capabilities by assessing how many requests it can handle concurrently and whether it slows down or still responds well after scaling.
- UI Testing: Evaluate how easy-to-use the chatbot and whether messages appear fast.
Step 8. Deploy Your Chatbot
After your chatbot is tested, the next (but not final) step is to deploy it for real users. Here’s what you need to do to ensure seamless deployment and make your bot accessible:
Deploy with FastAPI
FastAPI is a common Python framework for creating APIs fast and effectively. You can wrap your LangChain chatbot logic in FastAPI routes, which means building an API endpoint to let users interact with the chatbot. Here’s a simple example of how to deploy with FastAPI:
from fastapi import FastAPIfrom pydantic import BaseModelfrom langchain_ollama import ChatOllamafrom langchain.prompts import PromptTemplatefrom langchain_core.output_parsers import StrOutputParser# Initialize FastAPIapp = FastAPI()# Input schemaclass Query(BaseModel): question: str# LangChain setupprompt = PromptTemplate( template="You are a helpful assistant. Question: {question} Answer:", input_variables=["question"])llm = ChatOllama(model="llama3.1", temperature=0)chain = prompt | llm | StrOutputParser()@app.post("/chat")async def chat(query: Query): response = chain.invoke({"question": query.question}) return {"answer": response}Dockerize the app
Docker helps package your RAG chatbot into a container, allowing you to take and deploy it anywhere. Here’s an example of using Dockerfile to dockerize the app:
# Use a Python base imageFROM python:3.10-slim# Set working directoryWORKDIR /app# Copy project filesCOPY . /app# Install dependenciesRUN pip install --no-cache-dir fastapi uvicorn langchain-ollama langchain-core# Expose the app portEXPOSE 8000# Run the FastAPI serverCMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]Then, build and run your container:
docker build -t chatbot-app .docker run -p 8000:8000 chatbot-appDeploy to the cloud
Once dockerized, you can deploy your chatbot to cloud platforms:
- AWS (Amazon Web Services): Deploy with Amazon ECS or Elastic Beanstalk for container deployment. You can also store secrets in AWS Secrets Manager and scale with Auto Scaling.
- GCP (Google Cloud Platform): Use Cloud Run for fully managed containers. It automatically scales based on traffic.
- Azure: Leverage Azure Container Apps or Azure App Service for simple container deployments
- Railway: A developer-friendly platform for fast app deployment. Upload your code to a repo, set environment variables, and let Railway take care of containerization.
Advanced Features of RAG Chatbots

We have given you a comprehensive guide to build a simple RAG chatbot. If you want to enhance its accuracy, flexibility, scalability, and more specialized domain knowledge, you should consider integrating the following advanced features:
Multimodal RAG
Many real-world conversations may involve other multimodal information beyond text. Users may want to ask about images, audio, and videos; besides, external databases may store these data types. For example, a healthcare provider may want its chatbot to retrieve and analyze a medical image.
If you want your bot to handle such different inputs, you should add multimodal capabilities to your chatbot. This is often done by combining text-based LLMs with speech or image encoders (e.g., CLIP). These specialized encoders extract relevant non-text data.
One common method today is to turn multimodal data into text (e.g., captioning images or transcribing audio) before retrieval, as most tools (like LLMs or embedding models) still work best with text. Several RAG frameworks like LangChain haven’t natively supported multimodal extraction, while others are experimenting with it, but mainly succeed in image extraction.
Self-Tuning Retrieval
Not all RAG systems can successfully retrieve the most relevant, accurate information on the first try. To solve this problem, self-tuning retrieval can be adopted in your RAG chatbot, helping it dynamically enhance its own retrieval process and responses, often through learning from user feedback. There are many approaches to self-tuning retrieval:
- Relevance feedback and reward-based learning allow your chatbot to assess whether users find its response helpful and modify its retrieval weighting accordingly.
- Self-Reflective RAG (Self-RAG) leverages special tags to guide an LLM to extract documents, evaluate their relevance, and create better answers.
- Self-Routing RAG (SR-RAG) lets an LLM make its own decisions on whether it should pull from external databases or use its core knowledge bases.
Besides, researchers have been experimenting with Self-Adaptive Multimodal RAG (SAM-RAG), which is designed specifically for multimodal RAG. It actively filters relevant documents, evaluates the quality of the extracted data, and selects the best mix of multimodal sources for the response.
Hybrid Search Approaches
Some knowledge-intensive tasks don’t just require semantic search but also exact keyword matches. For example, when a customer asks about “affordable wireless speakers under $200,” the chatbot searches for not only terms similar to “affordable wireless speakers” but also exact prices below $200.
If your chatbot aims for hybrid search, choose retrieval systems that support both vector search and traditional keyword search (BM25). Some common systems include Weaviate, Elasticsearch, and Pinecone.
Industry-Specific Models
Your RAG chatbot may serve domain-specific tasks that involve piles of jargon and specialized knowledge. In this case, general-purpose models may not interpret the queries and process domain-specific data as well as industry-specific models. Worse, they may generate inaccurate and unreliable responses. To address this challenge, select and integrate domain-specific LLMs (like FinBERT for finance or BioBERT for medical) into your RAG pipeline.
Federated Systems
Many businesses don’t gather all their valuable data in one place. The data, accordingly, can be scattered across different databases, private servers, and cloud platforms. Instead of collecting data in a unified place, your chatbot can leverage a federated retrieval layer that queries various sources at once and merges results before delivering them to the LLM. Tools like LangChain’s MultiVectorRetriever help your chatbot connect to various vector stores, or you can build custom retrievers/APIs for a federated setup.
How Designveloper Helps Your Business Build a Powerful RAG Chatbot

Do you plan to build a RAG chatbot? Are you looking for expert help? If so, Designveloper is a perfect fit for your RAG journey. As a leading software and AI development company in Vietnam, we have an excellent team of 100+ developers, designers, AI specialists, and other talents who have implemented more than 200 successful projects. Our expertise spans across 50+ modern technologies and industries (e.g., finance, education, and healthcare).
We also make an active investment in integrating emerging tools, like LangChain, Rasa, AutoGen, and CrewAI, to deliver reliable solutions that connect seamlessly with your existing knowledge bases and systems. These products integrate RAG to generate accurate, context-aware responses.
Further, we add advanced features to empower their capabilities, such as persistent memory for multi-turn interactions, API connectivity for live data retrieval, and multi-tool integration. Whether you need a simple or advanced chatbot, Designveloper has the right expertise and tools to deliver. Don’t hesitate to contact us and discuss your idea further!
FAQs
How is the RAG technique applied to building a chatbot?
RAG (Retrieval-Augmented Generation) improves the natural capabilities of LLM-powered chatbots: retrieval and generation. Today’s available RAG frameworks offer components to help your chatbot extract real-time, up-to-date, and relevant information from external sources and generate context-aware, factual responses. Without RAG, chatbots may depend only on their core knowledge base, which may be outdated and lack specialized knowledge to complete specific tasks (i.e., related to legal services or medical diagnosis).
Can a RAG chatbot work with local or open-source LLMs?
Yes, a RAG chatbot not only works with proprietary or closed language models, like OpenAI’s GPT. Instead, you can integrate the chatbot with open-source models (e.g., LLaMA 2, Falcon, or Mistral) that can run locally on your own devices. Working with these models, you’ll have more control over data privacy, reduce costs, and minimize dependence on commercial APIs. However, using them locally may require stronger hardware to let these models work efficiently.
What strategies can I implement to reduce hallucinations in my RAG chatbot?
Even built with RAG, your chatbot can still make up its responses. To mitigate this challenge, you can adopt the following approaches:
- Use high-quality or self-tuning retrievers: Ensure your RAG system extracts the top-N documents or has advanced capabilities to evaluate and fine-tune its retrieval process.
- Implement rerankers: Re-order retrieved information to prioritize the most pertinent data.
- Attach citations: Make your chatbot link back to the original source to back up its responses.
- Set constraint parameters in response generation: Guide the chatbot to say “I don’t know” if it finds no reliable data to create reliable, relevant responses.
- Perform continuous assessment: Test your chatbot with real queries, gather user feedback, and refine its retrieval system.
Do I need an internet connection or cloud services to build a RAG chatbot?
No, you can build your RAG chatbot offline if you store your data locally and run an open-source LLM on your private server or your own devices. However, this setup may require more powerful hardware and struggle with scalability in comparison with using cloud servers.


{kind=link}
Hi my family member I want to say that this post is awesome nice written and come with approximately all significant infos I would like to peer extra posts like this
Your writing has a way of making even the most complex topics accessible and engaging. I’m constantly impressed by your ability to distill complicated concepts into easy-to-understand language.
I was recommended this website by my cousin I am not sure whether this post is written by him as nobody else know such detailed about my difficulty You are wonderful Thanks
Usually I do not read article on blogs however I would like to say that this writeup very compelled me to take a look at and do it Your writing style has been amazed me Thank you very nice article