
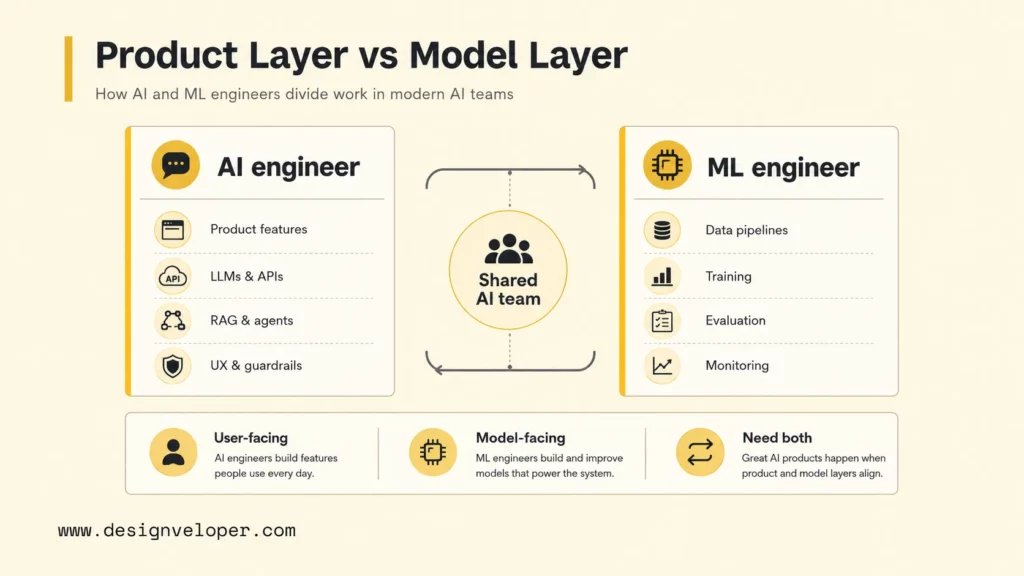
AI engineer vs ML engineer is mainly a product-layer versus model-layer distinction. An AI engineer turns models, APIs, prompts, retrieval systems, agents, and business workflows into usable product features. A machine learning engineer builds, trains, evaluates, deploys, and monitors models and data pipelines. The roles overlap, but the center of gravity is different: AI engineers make AI useful inside applications, while ML engineers make model behavior reliable, measurable, and scalable.
The distinction matters because AI teams are changing quickly. The World Economic Forum Future of Jobs Report 2025 lists AI and machine learning specialists among the fastest-growing roles through 2030, while the McKinsey 2025 State of AI survey says many organizations are already experimenting with or scaling agentic AI systems. Companies now need people who can ship AI features into products and people who can make the underlying model systems dependable.
Quick summary: hire or assign AI engineers when the work is about assistants, copilots, retrieval-augmented generation, workflow automation, tool use, user experience, and production integration. Hire or assign ML engineers when the work is about datasets, training pipelines, evaluation, fine-tuning, model performance, MLOps, and governance. Strong AI products usually need both skill sets, even when one person covers both in a small team.
AI Engineer Vs ML Engineer: Key Differences
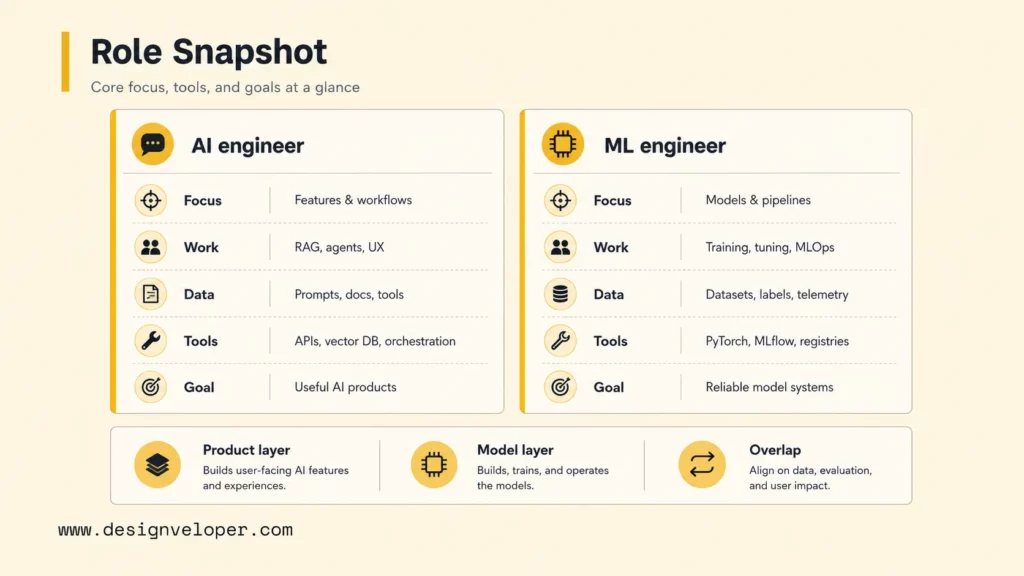
The simplest way to compare the two roles is to ask where each role spends most of its time. AI engineers usually work closer to users, products, APIs, and workflows. ML engineers usually work closer to data, training, model evaluation, deployment pipelines, and performance monitoring. The table below gives a compact view before the article goes deeper.
| Dimension | AI engineer | ML engineer |
|---|---|---|
| Primary Approach | Integrates existing and custom models into product workflows, often through APIs, prompts, tools, retrieval, orchestration, and application logic. | Builds and operates model pipelines, from data preparation and feature engineering to training, evaluation, deployment, and monitoring. |
| Core Focus | User-facing AI behavior, business workflow automation, agent design, response quality, guardrails, and product experience. | Model quality, data quality, training reproducibility, inference performance, drift monitoring, and statistical evaluation. |
| Typical Data Type | Documents, support tickets, user prompts, tool outputs, knowledge bases, CRM records, workflow events, and application context. | Structured datasets, labels, features, embeddings, experiment outputs, training data, validation data, and production telemetry. |
| Math Depth | Needs practical understanding of model behavior, evaluation, retrieval, and probability, but often less deep mathematical modeling than ML engineering. | Needs stronger statistics, optimization, model evaluation, data science, and sometimes deep learning or domain-specific modeling depth. |
| Main Tools | OpenAI APIs, Anthropic APIs, Azure AI, LangChain, LlamaIndex, vector databases, RAG pipelines, agent frameworks, backend services, observability tools, and product analytics. | Python, PyTorch, TensorFlow, scikit-learn, Spark, feature stores, MLflow, Kubeflow, SageMaker, Vertex AI, Airflow, model registries, and monitoring platforms. |
| Primary Goal | Deliver AI features that solve real user and business problems safely inside a software product. | Deliver models and ML systems that are accurate, reliable, reproducible, governable, and efficient in production. |
The comparison is not a hierarchy. AI engineers and ML engineers solve different parts of the same delivery problem. A product chatbot may fail because the prompt and handoff are weak, which is an AI engineering problem. A fraud model may fail because the training data no longer matches production behavior, which is an ML engineering problem.
AI Engineers In The Product Layer
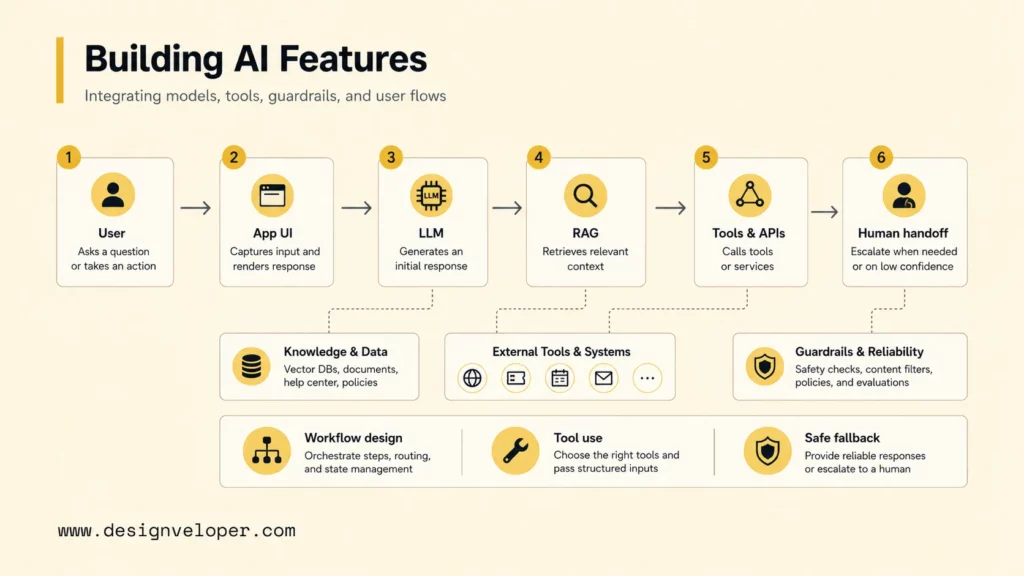
AI engineers work in the product layer because modern AI value often appears when a model becomes part of a real user journey. A model API by itself does not know the business rules, permissions, data sources, escalation path, or user interface. An AI engineer connects those pieces so the AI feature behaves like part of the product rather than a demo beside the product.
AI engineers turn models into product features by deciding what the AI feature should do, what data it can access, what tools it can call, what the user sees, and how failure is handled. For example, a customer-support assistant may need retrieval from a help center, ticket creation in Zendesk, order lookup in Shopify, and escalation to a human agent. The AI engineer designs the flow, tests the edge cases, and works with backend engineers to expose safe tools.
AI engineers also connect LLMs, APIs, tools, and business workflows. OpenAI’s 2025 launch of the Responses API and agent-building tools shows how AI application development is moving toward tool use, tracing, evaluations, and workflow orchestration. Those capabilities shift AI engineering away from one-off prompt writing and toward product-grade agent behavior.
Building agents, RAG flows, and AI product behavior requires a practical architecture mindset. An AI engineer may choose a vector database for document search, a reranker for retrieval quality, a policy layer for tool permissions, and an evaluation suite for expected answers. The AI engineer also has to decide when a model answer is enough, when the product should call a tool, and when the experience should ask a human.
Guardrails, reliability, and user experience are part of the AI engineer’s day-to-day work. The NIST AI Risk Management Framework emphasizes trustworthy AI characteristics such as validity, reliability, safety, security, accountability, transparency, explainability, privacy, and fairness. AI engineers translate those principles into concrete product controls, such as allowed actions, refusal rules, answer citations, audit logs, approval steps, and user-visible fallback behavior.
ML Engineers In The Model Layer
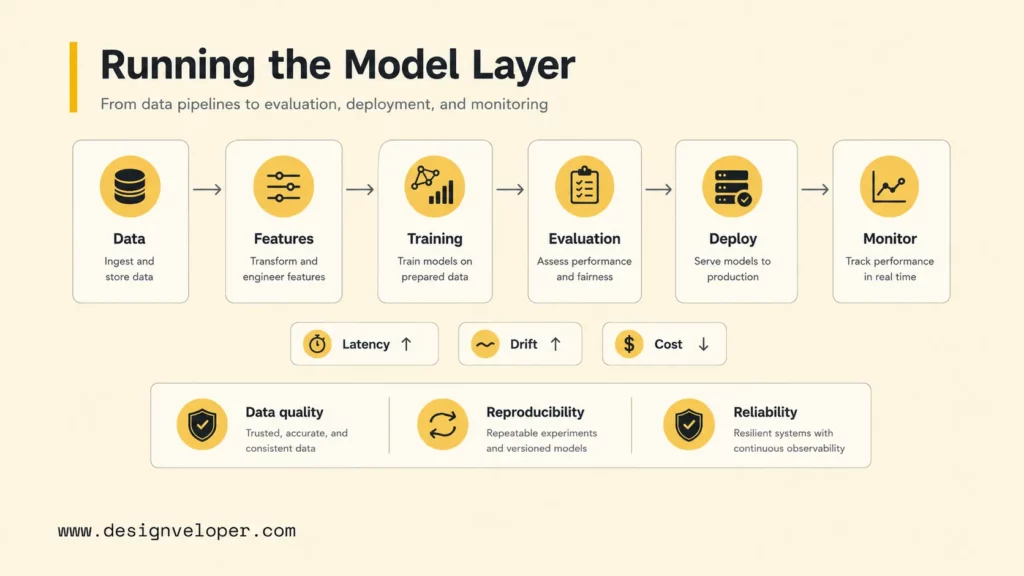
ML engineers work in the model layer because model quality depends on data, training, evaluation, deployment, and monitoring. A machine learning engineer is often responsible for the systems that turn raw data into reliable model predictions, then keep those predictions useful after the model meets real users, new data, and changing business conditions.
Preparing data and building model pipelines is a core ML engineering responsibility. The ML engineer may clean data, build feature pipelines, manage labels, split training and validation datasets, and make the pipeline reproducible. Data quality is not a small detail. A model trained on biased, incomplete, stale, or poorly labeled data can create unreliable product behavior even when the application layer is well designed.
Training, fine-tuning, and evaluating models are also central to the role. An ML engineer might train a recommendation model, fine-tune a classifier, evaluate an embedding model, or compare model versions against a benchmark. The Stanford 2026 AI Index tracks rapid changes in AI capability, research, education, and deployment, which reinforces why model teams need disciplined evaluation rather than assumptions about the newest model release.
Improving performance, reliability, and scale means looking at latency, throughput, inference cost, accuracy, calibration, drift, and failure patterns. A model that performs well in a notebook may still be too slow, expensive, fragile, or hard to monitor in production. ML engineers work with infrastructure, backend, and data teams to make model serving stable enough for business use.
MLOps, monitoring, and model governance are the long-term operating layer. Google Cloud’s MLOps continuous delivery guidance frames MLOps around automation and monitoring across ML construction, testing, release, deployment, and infrastructure management. AWS also treats model monitoring as a first-class production concern in its Machine Learning Lens monitoring guidance. Those practices sit squarely in the ML engineer’s world.
Collaboration Across The AI Stack
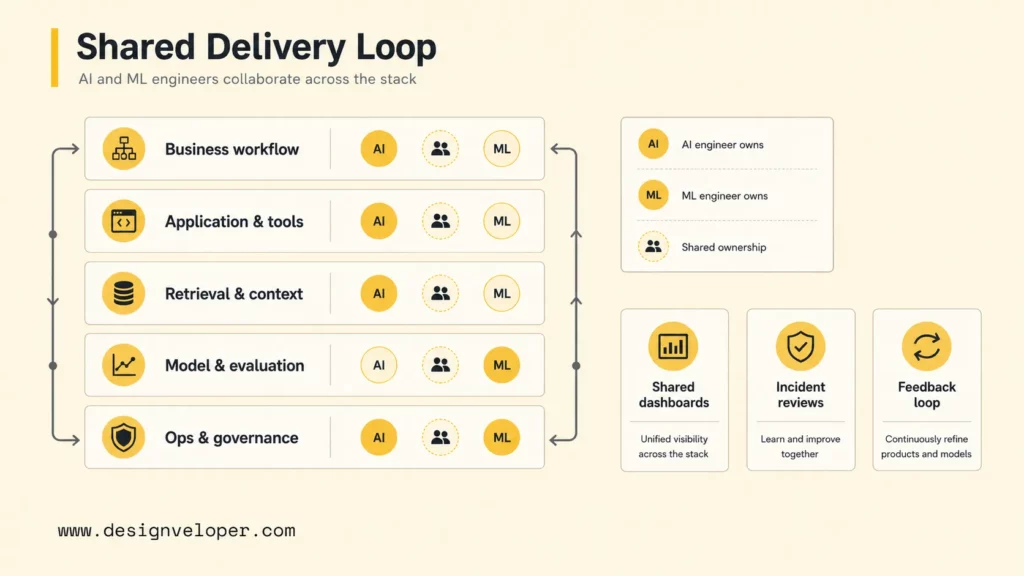
AI engineers and ML engineers collaborate because AI products need both product behavior and model discipline. The work moves from model capability to user experience, then back again when production feedback reveals model gaps, data gaps, or workflow gaps. The best teams treat the stack as shared responsibility, not a handoff line.
Moving From Model Capability To Product Experience
Moving from model capability to product experience requires translation. An ML engineer may deliver a model that classifies invoices, predicts churn, ranks documents, or detects anomalies. An AI engineer turns that capability into an application flow: upload a file, extract fields, ask clarifying questions, show confidence, request approval, write the result into the right system, and expose failures clearly.
A practical delivery artifact is a capability-to-experience map. The map lists the model output, the user action, the business rule, the UI response, the fallback path, and the owner. The map helps teams avoid a common failure: treating model output as the finished feature.
Sharing Responsibility In Deployment And Monitoring
Deployment and monitoring belong to both roles because production AI can fail at several layers. The model can drift. Retrieval can return weak context. A tool call can fail. A prompt change can break an edge case. A user can ask for an unsafe action. A queue can route an escalation to the wrong team.
A healthy AI team monitors several layers at once:
- Model metrics: accuracy, recall, precision, calibration, drift, latency, and cost.
- Retrieval metrics: source coverage, search relevance, citation quality, and unanswered intent.
- Product metrics: task completion, abandonment, escalation rate, user satisfaction, and repeat usage.
- Risk metrics: unsafe outputs, privacy events, hallucination reports, policy violations, and human override rate.
AI engineers usually own the product and workflow metrics. ML engineers usually own model and data metrics. Both roles need access to shared dashboards and incident reviews.
Blurring Boundaries In Smaller Teams
Smaller teams often blur the boundary because hiring one specialist for every AI layer is expensive. A senior backend engineer may become the AI engineer for an LLM feature. A data scientist may become the ML engineer for a prediction pipeline. A full-stack engineer may handle prompts, APIs, data cleaning, and evaluation during an early prototype.
Blended roles can work when the system is low-risk and the team is honest about gaps. The risk grows when a single generalist owns regulated data, custom model training, production infrastructure, user experience, and governance without review. Smaller teams should use checklists, code review, model review, and staged rollout to compensate for narrower staffing.
Combining Product Thinking With Model Depth
The strongest AI teams combine product thinking with model depth. Product thinking keeps the team focused on user tasks, business value, and workflow fit. Model depth keeps the team honest about data limits, evaluation quality, and system reliability. Neither skill set is enough by itself for serious AI products.
Designveloper approaches AI delivery from this combined perspective. As an AI development services partner, we connect product engineering, workflow mapping, LLM integration, RAG design, testing, monitoring, and human approval flows so AI features are useful after launch, not only impressive in a prototype.
How LLMs And Agents Are Changing Both Roles
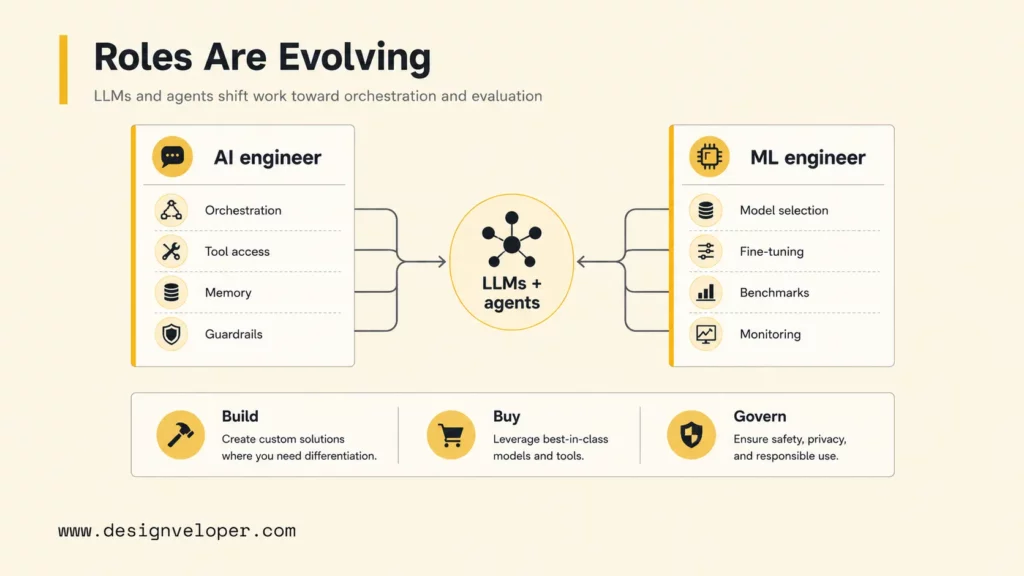
LLMs and agents are changing both roles by shifting more work from custom model creation toward orchestration, evaluation, data access, and workflow ownership. AI engineers are becoming more workflow focused, while ML engineers are expanding into evaluation, governance, fine-tuning, and model selection across foundation-model ecosystems.
AI engineers are becoming more workflow focused because LLM applications often succeed or fail outside the model. Retrieval quality, tool permissions, prompt structure, memory strategy, human review, and business-system integration can matter more than small differences between foundation models. The Stack Overflow 2025 AI survey section shows that AI tools and agents are now part of everyday developer workflows, but the same survey also reports lower positive sentiment than previous years. That mix of adoption and caution is exactly why AI engineering needs evaluation and oversight.
ML engineers are expanding beyond classical model training because many teams now start with foundation models instead of training from scratch. ML engineers still need core ML depth, but they may spend more time on model evaluation, fine-tuning strategy, synthetic data review, embedding quality, benchmark design, cost-performance tradeoffs, and monitoring model behavior across real user tasks.
Foundation models are shifting the build-versus-buy boundary. A team may buy model access through OpenAI, Anthropic, Google, AWS, or Azure, then build proprietary value in retrieval, workflow integration, domain data, product experience, and governance. A team may still build or fine-tune custom models when proprietary data, latency, cost, privacy, or domain accuracy requires it.
Team boundaries are becoming less rigid because agentic AI combines software engineering, data engineering, ML evaluation, security, product design, and operations. McKinsey’s 2025 research on AI agents reports that organizations are experimenting with and scaling agentic systems, but many still struggle to move from pilots to enterprise value. That reality makes cross-functional role clarity more important, not less important.
AI Engineering Vs Software Engineering
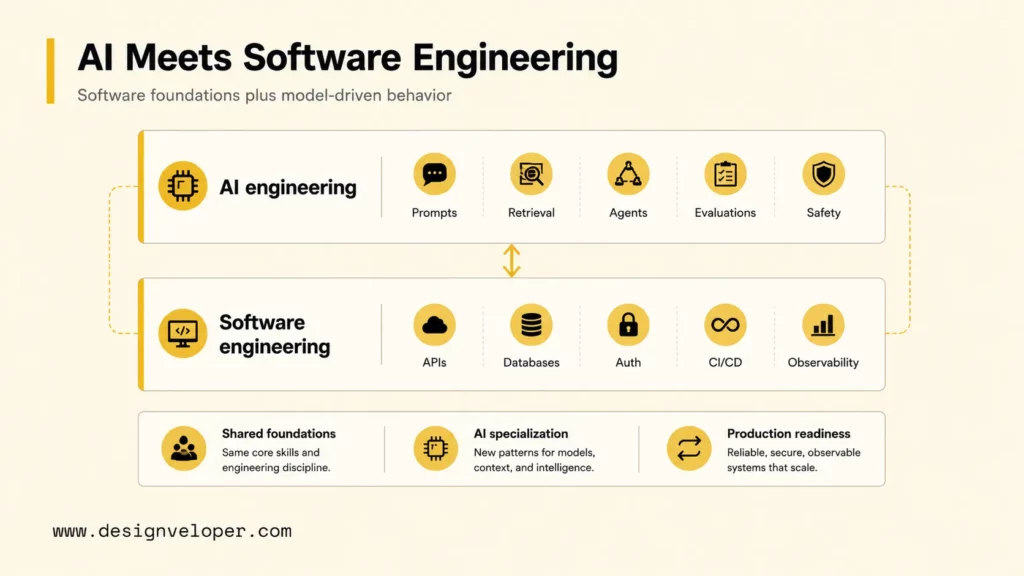
AI engineering is not a replacement for software engineering. AI engineering is a specialization that extends software products with model-driven behavior, retrieval, prompts, agents, evaluations, and guardrails. The related keyword ai engineer vs software engineer is useful because many teams ask whether a strong software engineer can simply own AI work. Sometimes the answer is yes for simple integrations, but advanced AI systems add new concerns.
Software engineers build general product systems: APIs, databases, authentication, permissions, billing, user interfaces, background jobs, CI/CD, observability, and infrastructure. Those foundations still matter. An AI feature that lacks access control, tests, logging, retries, and secure deployment is not production-ready, even when the model output looks impressive.
AI engineers extend products with model-driven capabilities. An AI engineer may add a retrieval pipeline to a document product, an assistant to a finance workflow, a customer-support bot to a help desk, or an agent that updates records after human approval. The AI engineer must understand software architecture and the behavior of probabilistic systems.
Prompt, retrieval, and evaluation add new engineering concerns. Traditional software tests often check deterministic outputs. AI systems need scenario tests, golden datasets, human review loops, red-team cases, answer-quality rubrics, tool-call validation, and monitoring for unexpected behavior. NIST’s AI RMF is useful here because AI engineering must treat trustworthiness as an engineering responsibility rather than a policy slogan.
Software foundations still underpin AI delivery. The best AI engineers are usually strong software engineers with added depth in LLMs, retrieval, agent workflows, evaluation, and AI safety. The best ML engineers also need software engineering habits because notebooks, experiments, and models must eventually become versioned, observable, and maintainable systems.
When Teams Need AI Engineers, ML Engineers, Or Both
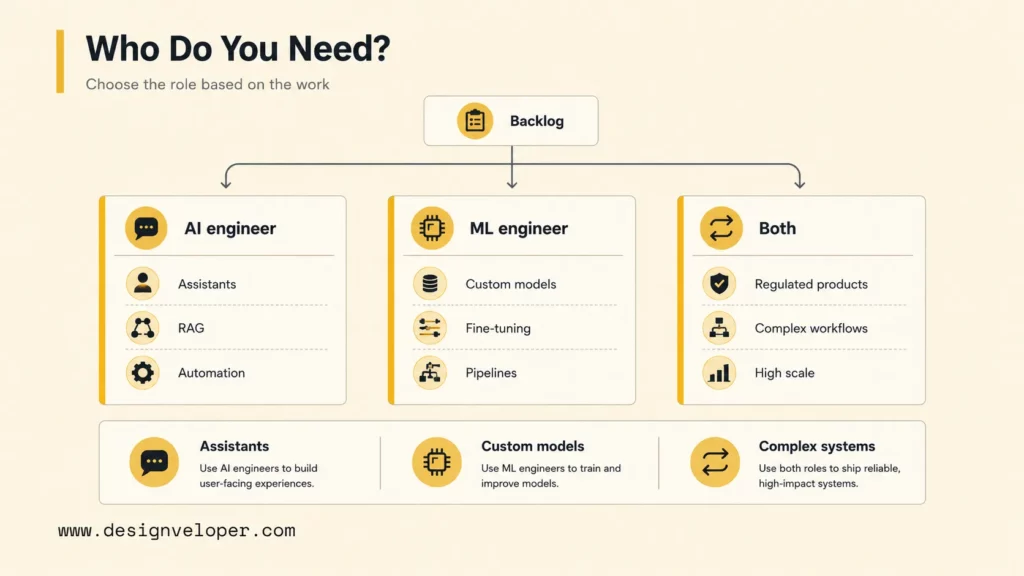
Teams need AI engineers, ML engineers, or both depending on whether the business problem is mainly product integration, model development, or a complex mix of both. The decision should follow the work, not the job title. A chatbot backed by existing APIs may need more AI engineering. A proprietary demand-forecasting system may need deeper ML engineering. A regulated AI product may need both from day one.
AI Engineers For Assistants, Automation, And AI Features
Teams need AI engineers when the product work centers on assistants, copilots, workflow automation, RAG systems, AI search, customer-service automation, document intelligence, internal tools, or agentic workflows. The AI engineer designs the user journey, integrates model APIs, connects business systems, writes guardrails, creates evaluations, and works with product designers to make the experience understandable.
A practical hiring signal is the backlog. If the backlog says “connect the AI assistant to CRM,” “build a RAG flow over policy documents,” “add a human approval step,” “measure answer quality,” or “let the agent create tickets safely,” the team likely needs AI engineering skill.
ML Engineers For Custom Models, Evaluation, And Optimization
Teams need ML engineers when the work depends on custom models, domain-specific performance, large datasets, fine-tuning, model comparison, inference optimization, or production ML pipelines. A fraud model, recommendation engine, computer vision classifier, demand forecasting model, or risk-scoring system usually needs ML engineering depth.
A practical hiring signal is the data pipeline. If the backlog says “build a labeled dataset,” “train a model,” “monitor feature drift,” “optimize inference latency,” “compare fine-tuned models,” or “set up a model registry,” the team likely needs ML engineering skill.
Both Roles For Complex AI Products
Complex AI products need both roles because model performance and product behavior interact. A legal document assistant may need ML engineers to evaluate retrieval, embeddings, and answer accuracy, while AI engineers design the editing workflow, permissions, user interface, citations, and escalation rules. A healthcare triage tool may need ML engineers for model validation and AI engineers for compliant workflow design.
Designveloper’s own project portfolio includes document-heavy, healthcare, HR, finance, and operational products such as Lumin document workflows, HRM internal workflow software, and Song Nhi finance software. Those product categories show why real AI systems usually need both software-product judgment and model/data judgment.
Team Size And Product Complexity Change The Boundary
Team size changes how responsibilities are split. A startup may start with one senior engineer who handles LLM integration, backend services, retrieval, evaluation, and deployment. A growth-stage company may split AI engineering from ML engineering once the product has enough users, data, and risk. An enterprise may separate data engineering, ML engineering, AI product engineering, platform engineering, security, and governance.
The boundary should become more formal when the system affects revenue, safety, regulated decisions, sensitive data, or core operations. Formal ownership helps teams avoid silent gaps, such as nobody owning model drift, nobody reviewing prompt changes, or nobody measuring whether the AI feature actually improves the workflow.
The Product Layer And The Model Layer Need Each Other
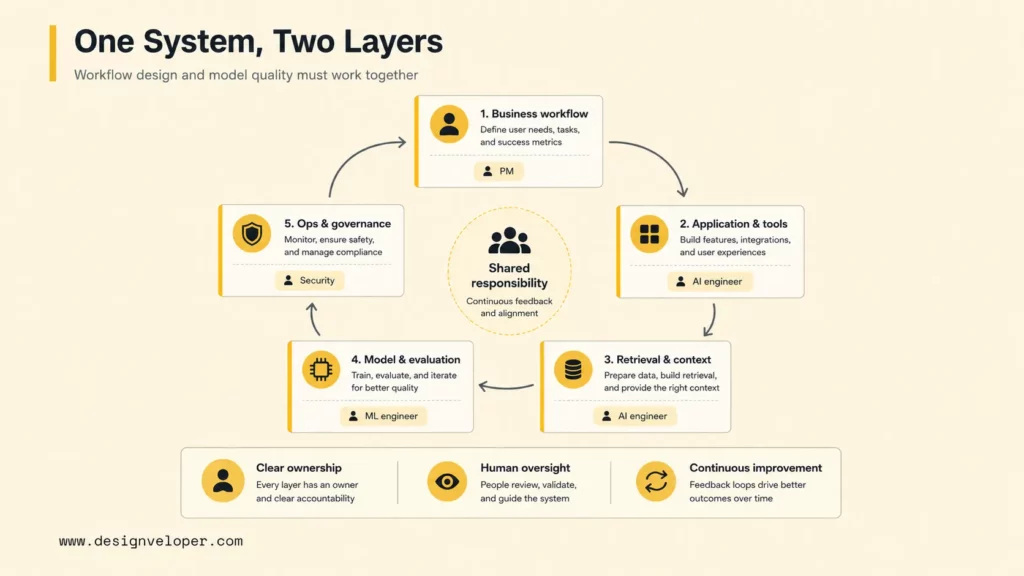
The product layer and the model layer need each other because AI value is created by a working system, not by a model or interface alone. A strong model without workflow design may sit unused. A polished AI interface without model discipline may produce confident errors. The best AI teams connect model quality, product behavior, business process, and human oversight into one delivery loop.
A useful operating model defines ownership across the stack:
| Layer | Primary owner | Review questions |
|---|---|---|
| Business workflow | Product manager, domain owner, AI engineer | What user task is being improved? What decision or action does AI support? |
| Application and tools | AI engineer, software engineer | What systems can the model access? What permissions and audit logs are required? |
| Retrieval and context | AI engineer, ML engineer, data engineer | Are sources current, relevant, secure, and traceable? |
| Model and evaluation | ML engineer, AI engineer | How are model quality, regressions, bias, hallucination, latency, and cost measured? |
| Operations and governance | Engineering, security, compliance, support | Who monitors incidents, approves changes, and reviews risky outputs? |
Designveloper helps teams build this delivery loop when AI work needs to move from concept to production. We combine custom software development, AI integration, workflow automation, testing, CI/CD, monitoring, and support so teams can make practical decisions about ai engineer vs ml engineer responsibilities without losing momentum.
FAQs About AI Engineer Vs ML Engineer
The most common questions about AI engineer and ML engineer roles focus on model training, LLM applications, team structure, and responsibility boundaries. The short answers below can help teams plan hiring, project ownership, and delivery responsibilities.
Do AI Engineers Train Models From Scratch?
AI engineers usually do not train models from scratch as their main responsibility. AI engineers may fine-tune prompts, evaluate model behavior, configure retrieval, test model outputs, or coordinate fine-tuning work. ML engineers are more likely to own training pipelines, model optimization, custom datasets, and deep evaluation.
Which Role Is More Involved In LLM Applications?
AI engineers are usually more involved in LLM applications when the work is about product behavior, agents, RAG, tool use, workflow automation, and user experience. ML engineers become more involved when the LLM application needs custom evaluation, fine-tuning, embedding experiments, model comparison, or performance optimization.
How Are LLMs Changing The Work Of AI And ML Engineers?
LLMs are pushing AI engineers toward workflow orchestration, tool access, guardrails, and evaluation. LLMs are pushing ML engineers toward model selection, fine-tuning strategy, benchmark design, data quality, retrieval evaluation, and production monitoring. Both roles now need stronger collaboration because LLM systems combine product behavior with model uncertainty.
When Does A Team Need Both Roles Instead Of One?
A team needs both roles when the AI product has custom data, production risk, regulated decisions, high usage, sensitive workflows, or measurable model-performance requirements. One generalist may be enough for a narrow prototype, but a production product with real users usually benefits from AI engineering for the product layer and ML engineering for the model layer.
How Do Smaller Teams Split AI And ML Responsibilities?
Smaller teams can split responsibilities by artifact. One engineer may own the application, prompts, tools, and user workflow. Another may own data preparation, evaluation, model monitoring, and MLOps. If one person owns both areas, the team should still run separate reviews for product behavior, data quality, security, model evaluation, and business impact.


{kind=link}