
An AI demo can impress a room in five minutes. A production-ready product has to work every day, with real users, messy data, changing workflows, security constraints, support requests, and business targets. That is why the journey from mvp to production is not a simple matter of adding more features. It is a shift from proving that an idea can work to proving that a system can be trusted, operated, improved, and scaled.
This distinction matters more now because AI adoption has moved beyond curiosity. McKinsey’s 2025 global survey reports that 88 percent of respondents say their organizations use AI in at least one business function, while only a smaller group reports significant value from AI. The gap is not usually caused by a weak demo. It is caused by unfinished product engineering.
This guide explains what changes after an AI MVP is validated, how teams can choose between evolution and rewrite, and why architecture, data flows, guardrails, testing, monitoring, and delivery discipline decide whether the product becomes useful in real operations.
Why An AI MVP Is Only The Beginning?
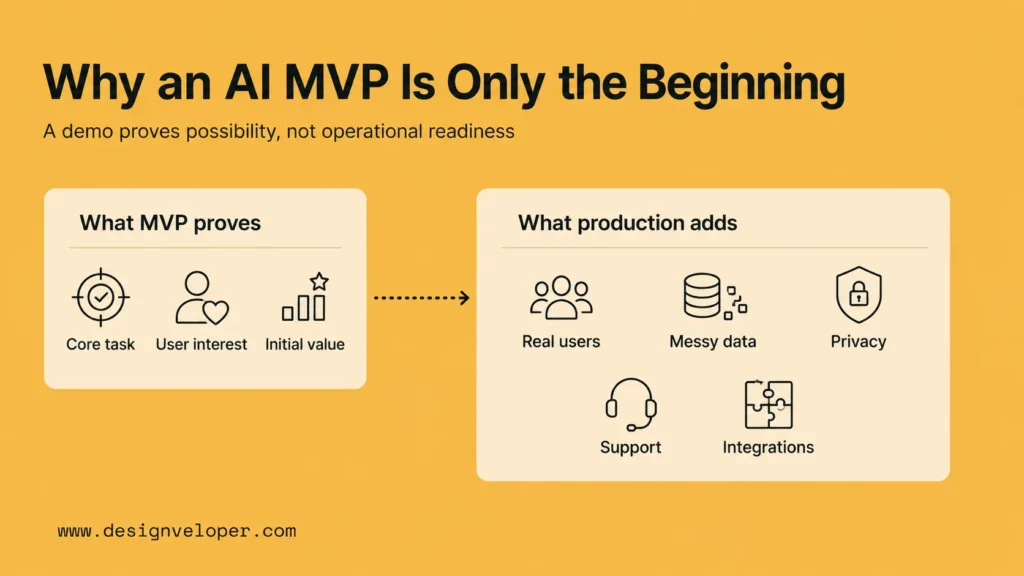
An AI MVP is useful because it reduces uncertainty. It can prove that users understand the concept, that a model can support the core task, and that stakeholders are willing to invest more time. However, an MVP is not designed to carry the full weight of a production product. It often uses simplified data, limited permissions, manual workarounds, and a narrow user journey.
The risk appears when a team treats a successful demo as proof that the system is ready for scale. The demo may be correct under controlled conditions, but production introduces usage spikes, edge cases, privacy obligations, user support, analytics, onboarding, and integrations with existing business systems.
A Strong Demo Does Not Prove Product Readiness
A polished AI MVP can hide fragile assumptions. The prototype may rely on a single prompt, a manually curated data set, a temporary vector store, or one developer’s local scripts. It may not yet have role-based access, audit logs, automated tests, cost limits, fallback paths, or recovery procedures.
For AI systems, product readiness also includes model-specific risks. The OWASP Top 10 for Large Language Model Applications highlights practical threats such as prompt injection, sensitive information disclosure, insecure output handling, excessive agency, and supply-chain risks. These risks rarely block a demo, but they matter once real customers, business data, and automated actions are involved.
Product-Market Fit And The Signals That Justify Scaling
Scaling should follow evidence, not enthusiasm. A team should see repeated usage, clear retention signals, willingness to pay or expand, and a measurable improvement in the workflow the AI product is meant to support. For an internal tool, the signal may be time saved, fewer manual handoffs, higher completion rates, or better quality control. For a customer-facing product, it may be activation, conversion, retention, support deflection, or revenue per account.
Good signals are behavioral. A stakeholder saying that the demo is exciting is helpful, but it is not enough. A stronger signal is when users return without being pushed, bring the tool into their daily process, ask for reliability improvements, and complain when the product is unavailable.
How Real Users, Data, And Workflows Change The Requirements
Real users do not behave like demo users. They upload incomplete documents, ask vague questions, use unexpected language, ignore instructions, and switch between tasks. Real data also changes the product. Documents vary in format, customer records contain duplicates, permissions become complicated, and integrations fail at inconvenient times.
As a result, the production backlog becomes broader than the MVP backlog. The team needs better input validation, data cleaning, retrieval quality checks, observability, admin controls, consent flows, escalation paths, and user education. At this point, the AI feature is no longer an isolated model call. It becomes part of a business workflow.
What A Production-Ready Product Really Requires
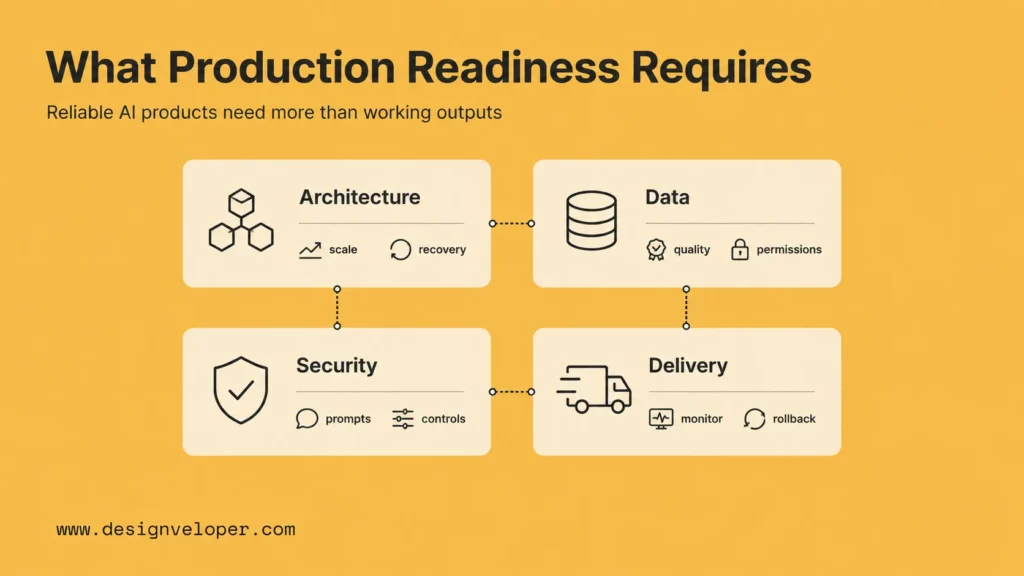
A production-ready AI product is a system that can deliver stable value under normal operating pressure. That means it must handle expected traffic, protect data, recover from failure, support change, and produce results that users can understand and trust. The product does not need to be perfect, but it must be engineered enough that the business can rely on it.
| Area | MVP question | Production question |
|---|---|---|
| Architecture | Can the main flow work? | Can the system scale, recover, and evolve? |
| Data | Can the model use a sample data set? | Can the product manage real permissions, freshness, quality, and lineage? |
| Security | Can users test it safely? | Can the business protect users, systems, prompts, outputs, credentials, and integrations? |
| Delivery | Can the team ship quickly? | Can the team release safely, monitor behavior, and roll back when needed? |
Stronger Architecture, Data Flows, And Integrations
Production architecture turns a clever workflow into an operational system. For an AI product, this may include API gateways, authentication, background jobs, queueing, caching, model routing, retrieval pipelines, data stores, analytics events, and integration layers for CRM, ERP, support, document management, or payment systems.
Data flow design becomes especially important. A retrieval-augmented generation product, for example, must decide how documents are ingested, chunked, embedded, indexed, refreshed, permissioned, and deleted. If these decisions are skipped, the product may answer from stale information, expose the wrong record, or become too expensive to operate.
Technical Debt Refactoring And Stronger Security
Technical debt is not automatically bad in an MVP. Early shortcuts can help the team learn quickly. Yet after validation, some shortcuts become risk. Hard-coded prompts, loosely protected admin tools, missing input limits, unreviewed dependencies, and manual deployment steps can slow the product at the exact moment it needs to become more reliable.
Security should move from informal checks to a repeatable engineering practice. The NIST Secure Software Development Framework gives teams a useful baseline for preparing the organization, protecting software, producing secure software, and responding to vulnerabilities. For AI products, that baseline should be extended with model, prompt, retrieval, and tool-use controls.
CI/CD, Automated Testing, And Continuous Monitoring
Reliable delivery depends on feedback loops. Continuous integration and delivery help teams release smaller changes, catch regressions, and recover faster. Google’s 2024 DORA research continues to frame software delivery around practical performance measures such as deployment frequency, lead time for changes, change failure rate, and failed deployment recovery time in the Accelerate State of DevOps Report.
AI products need the same delivery discipline plus AI-specific monitoring. Teams should track latency, cost per task, model errors, fallback rate, retrieval hit quality, hallucination reports, user corrections, escalation volume, and outcome metrics. Without monitoring, a team may not know whether a prompt change improved quality or quietly increased risk.
Choosing The Right Transition Path
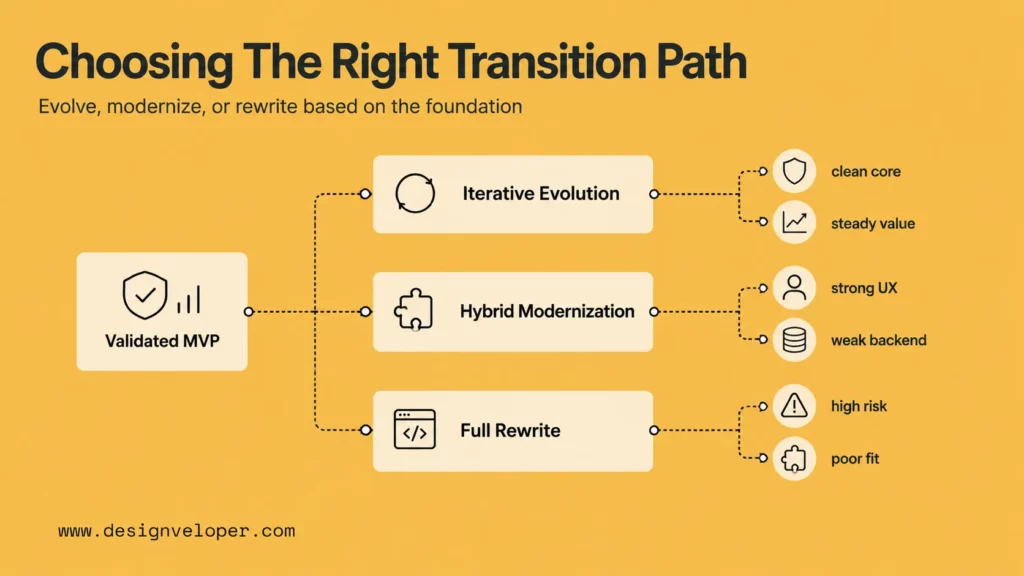
The right path from MVP to production depends on how much of the foundation still works. Some MVPs can evolve steadily. Others need partial modernization. A few should be rewritten because the prototype solved the wrong technical problem or cannot support the required scale, security, or workflow complexity.
The choice should be made with evidence. Teams should review architecture, code quality, data flow, model behavior, cost profile, integration requirements, compliance obligations, and the roadmap. The decision is not about pride in the prototype. It is about the cost of keeping it versus the cost of replacing it.
Iterative Evolution When The Core Foundation Still Works
Iterative evolution fits when the MVP has a clean enough architecture, a stable core workflow, and no serious security or data limitations. The team can harden the product in layers: improve authentication, add tests, refactor the most fragile modules, introduce monitoring, and expand integrations.
This path is usually best when users are already getting value and the product needs controlled improvement rather than a new foundation. It also protects learning. A full rewrite can accidentally discard useful details that emerged from real usage.
Hybrid Modernization When Only Part Of The System Needs To Change
Hybrid modernization works when part of the MVP is valuable but another part is blocking scale. For example, the front-end experience may be strong, while the back-end data pipeline is too manual. Or the model workflow may be useful, while the integration layer needs to be rebuilt for reliability and security.
This path lets the team preserve validated user experience while replacing weak infrastructure. It can also reduce business risk because users keep seeing progress while the engineering team improves the foundation behind the scenes.
Full Rewrite When Scale, Risk, Or Complexity Demand It
A full rewrite makes sense when the prototype cannot be made safe or maintainable at reasonable cost. Warning signs include a brittle data model, deeply coupled code, no clear ownership boundaries, missing security foundations, high operating cost, or a roadmap that requires capabilities the MVP was never designed to support.
Rewriting should still be disciplined. The team should preserve what was learned from users, write a clear product specification, define migration rules, and avoid rebuilding every experimental feature. The goal is not to make the system bigger. The goal is to make the validated product durable.
Why Product Engineering Matters More Than Model Choice
Model selection matters, but it rarely solves the whole product problem. A better model can improve reasoning, writing, coding, or multimodal analysis, but users experience the full system. They care whether the product understands context, respects permissions, completes the job, handles mistakes, and fits the workflow.
This is why production AI work quickly becomes product engineering. The model is one component inside a wider design that includes data, interface, actions, policies, testing, monitoring, and human review.
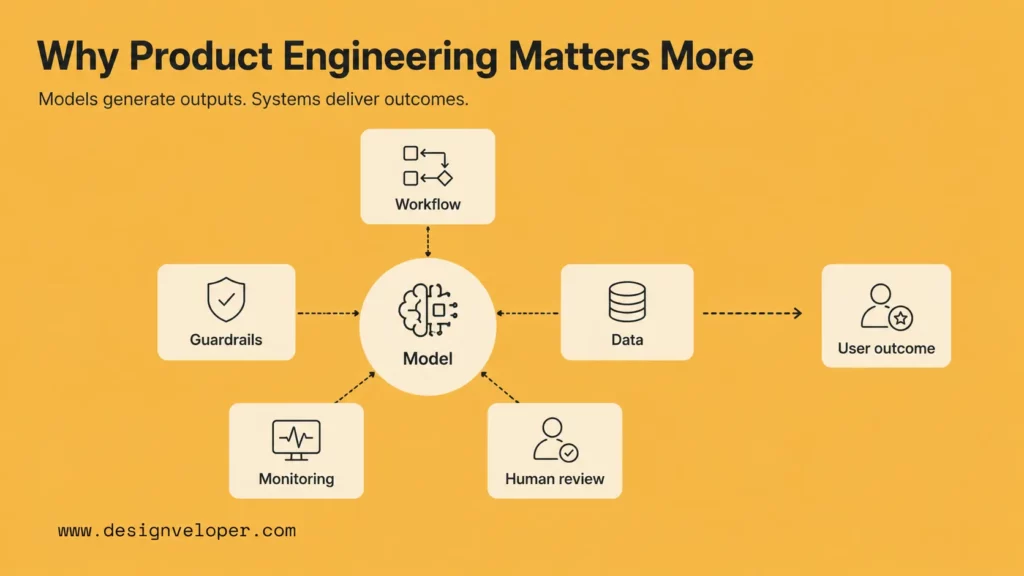
Models Generate Outputs, But Systems Deliver Outcomes
An AI model can produce an answer. A product must help the user finish a task. That difference changes the design. A document assistant should not only summarize a contract; it should show citations, preserve context, respect document access, and let the user act on the result. A support assistant should not only draft a reply; it should check order status, follow refund policies, and route uncertain cases to a human.
Outcome design requires systems thinking. Teams need to define what success means, what the AI is allowed to do, what it must not do, and how the product responds when confidence is low.
Workflow Design, Guardrails, And Reliability Shape Real Usability
Workflow design determines whether users trust the product. If the AI appears in the wrong place, asks for too much information, or produces answers without context, users may avoid it even when the model is powerful. Guardrails help by limiting unsafe actions, adding review steps, validating outputs, and keeping the product aligned with policy.
Risk frameworks can help teams structure this work. NIST’s AI Risk Management Framework and its generative AI profile give organizations a vocabulary for mapping, measuring, managing, and governing AI risk through resources such as the NIST AI Risk Management Framework. For product teams, this translates into practical controls: documented use cases, risk owners, evaluation criteria, incident processes, and continuous review.
Product Quality Depends On More Than AI Performance
AI performance is only one quality dimension. A production product also needs usability, accessibility, speed, data protection, supportability, cost control, and maintainability. A model that answers well but takes too long, costs too much, or cannot explain its sources may still fail as a product.
Teams should therefore test both model behavior and product behavior. Evaluation sets, red-team prompts, user acceptance tests, integration tests, and analytics reviews all answer different questions. Together, they show whether the product is useful, safe, and ready for broader rollout.
Where Business, IT, And Product Teams Need Expert Support
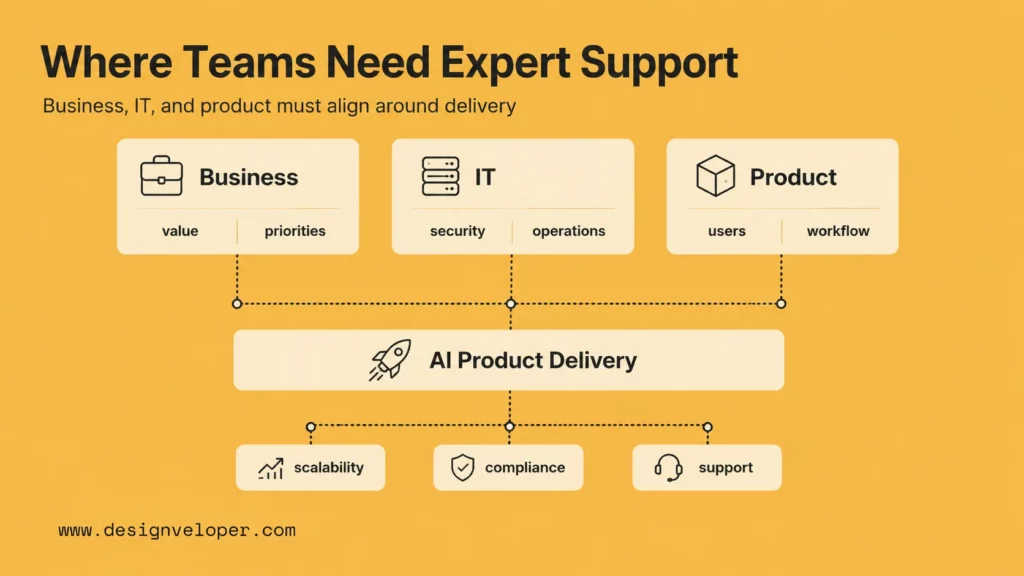
Moving an AI product beyond MVP requires shared decisions across business, IT, product, design, data, and engineering. The work often stalls when teams see the same prototype from different angles. Business leaders focus on value. IT leaders focus on security and maintainability. Product teams focus on users. Engineering teams focus on architecture and delivery risk.
Expert support is useful because the transition is both strategic and technical. A team must decide what to keep, what to rebuild, what to measure, and what level of operational risk is acceptable.
Aligning Business Goals With Technical Reality
The first alignment question is simple: what business outcome should this product improve? The answer may be faster support resolution, reduced manual document work, better lead qualification, shorter onboarding, or a new revenue feature. Once the outcome is clear, the technical team can judge whether the MVP architecture supports it.
This prevents overbuilding. It also prevents underbuilding. A product that handles sensitive documents, customer records, or automated decisions needs stronger controls than a lightweight internal writing assistant.
Evolving From A Small MVP Team To A Scalable Delivery Team
An MVP may be built by a small team moving quickly. A production product needs clearer ownership. Teams need product management, UX, engineering, QA, DevOps, security, data, and support responsibilities. They also need a delivery rhythm that can handle maintenance and new features at the same time.
That shift can feel slower at first, but it usually increases speed over time. Clear standards, automated tests, release practices, and monitoring reduce avoidable rework. They also make it easier for new engineers to join without depending on undocumented prototype knowledge.
Handling Scale, Compliance, And Workflow Complexity
Scale is not only traffic. It can mean more roles, more data sources, more markets, more approval paths, and more failure cases. Compliance can add requirements for access control, audit trails, retention, explainability, consent, or vendor review. Workflow complexity can require human-in-the-loop decisions, exception handling, and integration with legacy systems.
These issues should be designed before the rollout expands. Fixing them after users depend on the product is more expensive and riskier.
The Role Of The Right Technology Partner
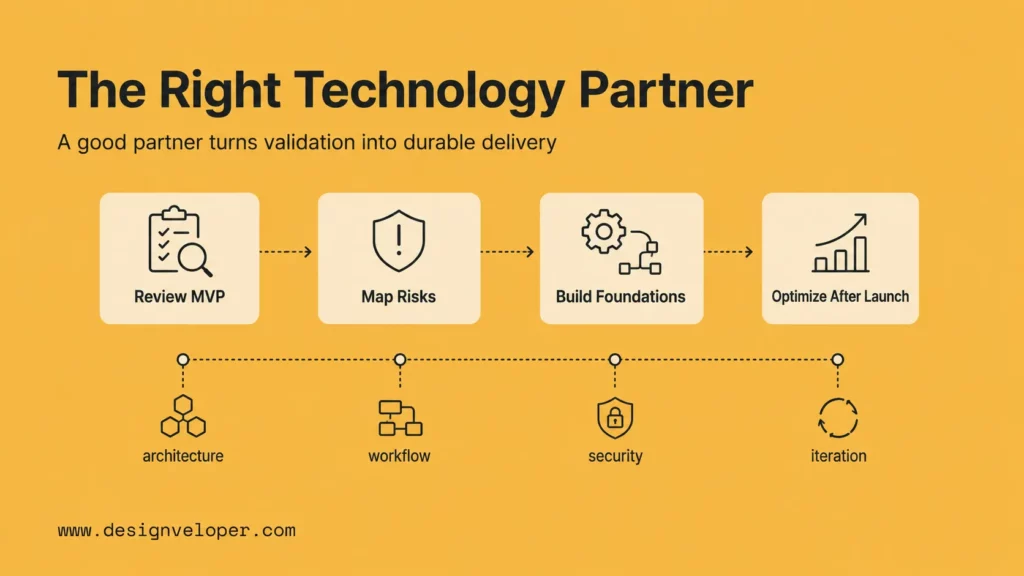
The hardest part of moving from an AI MVP to a production product is rarely validating the idea itself. The real challenge is turning that idea into a secure, scalable, and maintainable product. That requires product engineering, AI implementation skill, workflow analysis, and delivery discipline.
Designveloper supports this transition as an AI-first software and automation partner. Our AI development services focus on practical AI systems that improve efficiency, user experience, and business operations, while our broader web application development services cover the product foundations needed for real software delivery.
For teams moving beyond a demo, the most valuable partner is not simply a model integrator. It is a team that can review the MVP, identify product and architecture risks, design the right transition path, build the missing production layers, and keep improving the product after launch.
FAQs About Moving From AI MVP To Product
When Should A Team Evolve The MVP Instead Of Rewriting It?
A team should evolve the MVP when the core architecture is understandable, the main workflow is validated, security issues are manageable, and the roadmap does not conflict with the original foundation. Evolution is also better when users are already active and the business needs steady improvement without disrupting learning.
What Usually Breaks First When An AI MVP Starts Scaling?
The first weak points are often data quality, permissions, latency, cost, monitoring, and integration reliability. AI-specific issues also appear, including prompt drift, inconsistent retrieval results, unsupported edge cases, and weak escalation paths. These problems are manageable when the team instruments the product early.
What Should Teams Build First After MVP Validation?
Teams should build the foundations that reduce operational risk: authentication, role-based permissions, logging, automated testing, monitoring, data quality checks, cost controls, and a clear release process. After that, they can expand features with more confidence because the product has a safer base.
When Do Compliance Requirements Force Bigger Changes?
Compliance can force bigger changes when the product handles regulated data, personal information, financial decisions, healthcare workflows, contractual documents, or automated actions with business impact. Requirements may include audit logs, data retention policies, access controls, explainability, vendor review, and incident response procedures.
Why Does Product Engineering Matter So Much After The MVP Stage?
Product engineering connects the AI capability to a real user outcome. It covers architecture, UX, security, data flow, quality assurance, deployment, monitoring, support, and iteration. Without that layer, an AI MVP may remain a good demo. With it, the product can become a reliable part of the business.
Moving from mvp to production is the point where an AI idea becomes accountable. The right next step is to review the current foundation, define the production risks, choose the transition path, and build the system around the workflow users actually need.


{kind=link}