
AI hallucinations are false, unsupported, or invented outputs produced by an artificial intelligence system, often in language that sounds confident and useful. When people ask “what is AI hallucinations,” they usually mean the moment when a chatbot, large language model, image model, or AI agent presents something as true even though the system has not verified it. That can include a fake statistic, a nonexistent source, a wrong document summary, or a claim about completing an action that never happened.
The problem matters because modern AI systems can write fluently enough to hide uncertainty. A response may look polished, cite names, use technical vocabulary, and follow the requested format while still being wrong. OpenAI research on language model hallucinations describes hallucinations as confident answers that are not true and argues that many evaluation systems still reward guessing more than admitting uncertainty. In production software, that difference between “sounds right” and “is right” is where risk begins.
This guide explains what AI hallucinations are, why LLMs and ChatGPT make things up, what hallucinations look like in real workflows, and how teams reduce the risk with grounding, retrieval, verification, human review, and better system design.
Quick answer: treat AI output as low risk only when the task is reversible, the claim is not factual, and a person can easily check the result. Treat AI output as high risk when it affects money, health, legal language, security, customer commitments, code deployment, or business records. In high-risk workflows, a reliable system should retrieve trusted evidence, show citations, log tool use, allow uncertainty, and route important decisions to a reviewer.
| Reader question | Safe default | Why it matters |
|---|---|---|
| Can I use the answer as a draft? | Yes, if the task is low risk and easy to review. | Drafting, brainstorming, and summarizing are useful when the user stays responsible for verification. |
| Can I use the answer as a fact? | Only after checking a primary source. | LLMs can invent citations, numbers, names, deadlines, or product details that look real. |
| Can I let the AI take action? | Only with permission limits, logs, validation, and approval gates. | Agentic workflows can turn one unsupported answer into a record change, email, payment, or customer promise. |
For readers building AI products, the safest mental model is not “perfect model versus bad model.” The better question is whether the application can prove the answer. Designveloper’s guides to retrieval-augmented generation and AI agent architecture show how retrieval, tools, memory, and approval layers can be designed around that verification problem.
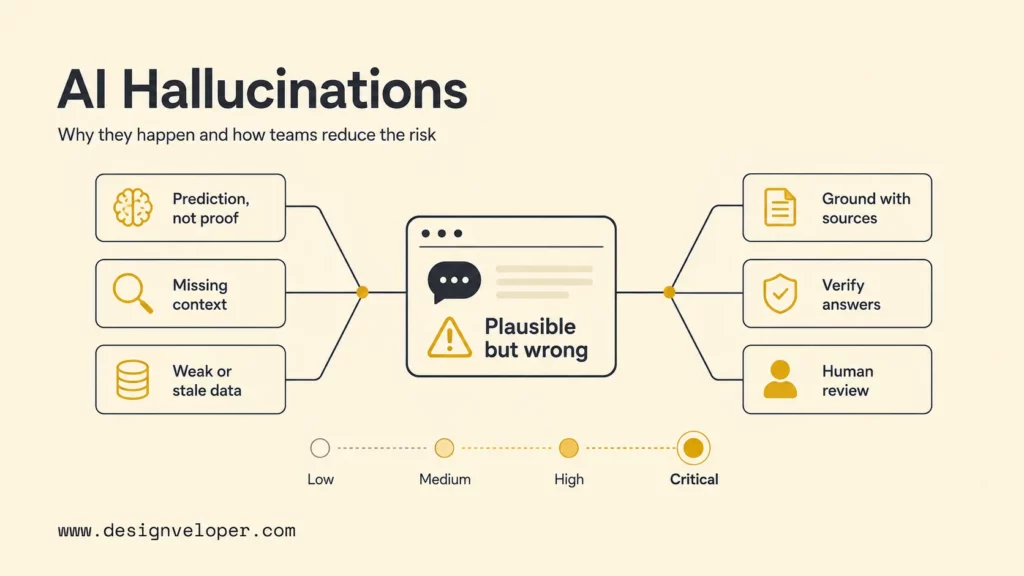
What Are AI Hallucinations?
AI hallucinations are outputs that appear plausible but are factually wrong, unsupported by the provided context, or impossible for the model to know. The term is most often used for generative AI systems such as large language models, chatbots, coding assistants, summarization tools, and multimodal models. IBM’s explainer on AI hallucinations frames the issue as false or misleading information generated by AI, while Google Cloud’s overview of AI hallucinations emphasizes responses that are inaccurate or fabricated.
A hallucination is not simply a typo or a minor wording issue. It is a reliability problem: the model produces output that users may treat as knowledge, evidence, or action. In a casual brainstorming session, the damage may be small. In customer support, finance, legal, healthcare, engineering, or compliance workflows, the same behavior can mislead people, waste time, or create operational risk.
Hallucinations can happen even when a model has been trained well. Generative models learn statistical patterns across language, code, and other data. They are designed to produce likely continuations, not to automatically prove every statement. Some models can use tools, search, retrieval, or databases, but those features must be designed, tested, and constrained carefully. Without reliable grounding, a model may fill missing information with a confident guess.
The safest way to think about hallucination is this: AI output is a draft of what might be useful, not proof of what is true. The more important the decision, the more the system needs source grounding, explicit uncertainty, verification steps, and human review.
The table below separates hallucination from nearby quality problems because different failures need different controls.
| Problem | What it means | Best first control |
|---|---|---|
| Hallucination | The model presents unsupported or false information as if it were true. | Ground the answer in retrieved evidence and require citations for factual claims. |
| Outdated answer | The model gives information that used to be true but changed after training or indexing. | Use fresh sources, live documentation, release notes, or a maintained knowledge base. |
| Bad instruction following | The model ignores format, policy, role, or workflow constraints. | Add validation, tests, structured outputs, and rejection rules before the answer reaches users. |
| Unsafe action | An agent performs or claims to perform a task without proper authorization or evidence. | Use tool permissions, audit logs, human approval, and action confirmation. |
Why LLMs And ChatGPT Make Things Up
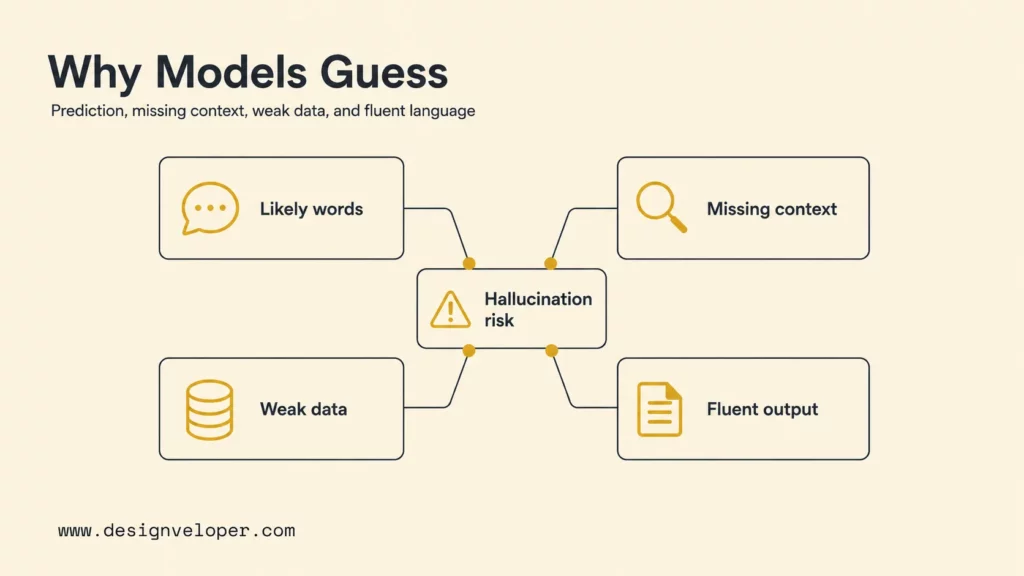
LLMs and ChatGPT make things up because they generate language from learned patterns under incomplete information. They do not naturally separate “likely text” from “verified fact” unless the surrounding system pushes them to do so. Training data, prompt wording, evaluation incentives, missing context, and user pressure can all increase the chance of an LLM hallucination.
LLMs Predict Likely Words Instead Of Verifying Facts
Large language models predict likely tokens based on context. That token prediction can produce accurate explanations when the prompt, training signal, and context align. It can also produce false details when the model has learned a pattern but lacks a verified fact. A model may know what a citation looks like, what a company profile usually includes, or how a legal answer is structured without knowing the correct citation, company fact, or legal rule for the current case.
This is why hallucinated citations are common. The model can imitate the shape of a reference because it has seen many references. That does not mean it has checked that the paper, author, URL, or quote exists. In an application, developers should treat citation generation as a retrieval and verification problem, not only a prompt-writing problem.
Missing Context Forces The Model To Fill In The Gaps
Missing context is one of the most practical causes of hallucination. If a user asks about a private policy, a recent product change, an internal database record, or a specific contract clause, the model may not have that information. Unless the system gives the model the right source or allows it to say “I do not know,” the model may infer an answer from surrounding patterns.
That gap is especially visible in enterprise chatbots. A support assistant may receive a customer question without account data. A document assistant may summarize only part of a PDF. A coding assistant may see one file but not the related configuration. In each case, the model can produce a useful-looking answer that is unsupported because the needed evidence was never available in the prompt.
Bad Or Biased Training Data Leads To Bad Patterns
Training data affects model behavior. If data contains outdated facts, biased examples, low-quality explanations, duplicated claims, or contradictory statements, a model may reproduce those patterns. Even high-quality training cannot guarantee current truth because facts change after training. Company prices, API limits, laws, product names, security guidance, and public statistics can all become stale.
This is why teams should avoid treating a model as a static encyclopedia. For factual and time-sensitive workflows, the system should retrieve current sources, show the source context to the model, and return links or evidence to the user. Grounding does not make hallucinations impossible, but it reduces unsupported guessing and gives reviewers something concrete to check.
Fluent Language Can Hide Weak Understanding
Fluent language makes hallucinations harder to catch. A chatbot can use confident wording, structured bullets, and a calm tone even when the answer is wrong. People often judge confidence, completeness, and readability as signs of correctness. That habit becomes dangerous when AI output is used in research, search, support, or decision workflows.
OWASP’s LLM09:2025 Misinformation guidance warns that overreliance happens when users place too much trust in LLM-generated content without verification. The risk is not only that the model is wrong. The risk is that people may copy the wrong output into code, documents, policy decisions, customer messages, or executive reports before anyone checks it.
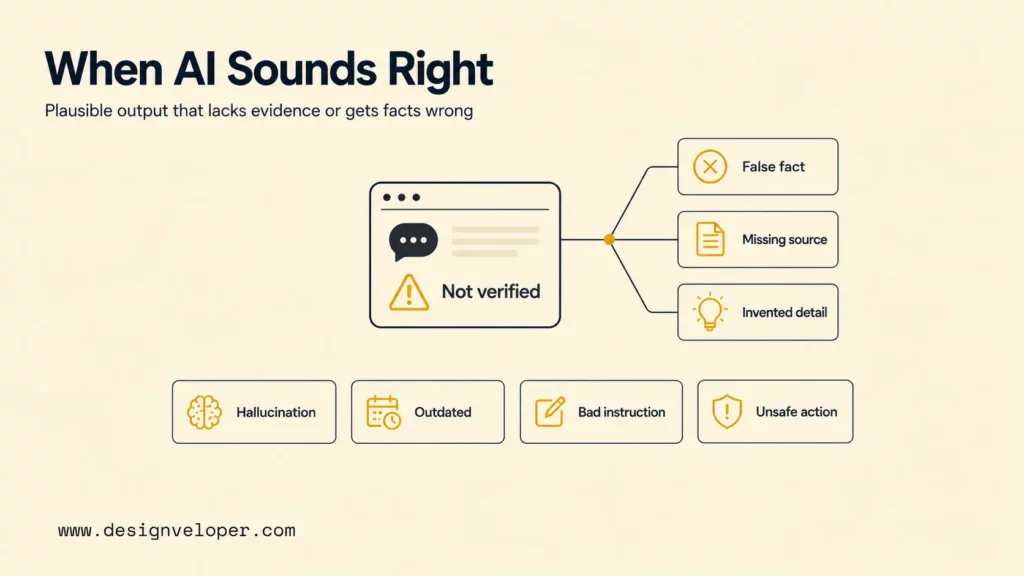
What Hallucinations Look Like In Practice

Hallucinations appear in many forms. Some are obvious, such as an invented link that returns a 404 page. Others are subtle, such as a summary that changes one condition in a contract or a chatbot answer that gives a mostly correct policy with one dangerous exception. Teams should define hallucination patterns for their own workflows so QA can test for them before launch.
- Fabricated facts, quotes, or statistics: The model invents numbers, attributes a quote to the wrong person, or states a trend without a source.
- Fake citations, links, and references: The model generates academic papers, URLs, case names, release notes, or documentation pages that do not exist.
- Incorrect summaries of real documents: The model sees a real document but omits important limitations, combines unrelated clauses, or reverses the meaning of a passage.
- Made-up actions, capabilities, or completed tasks: An AI agent claims it sent an email, updated a ticket, checked a database, or completed a file operation when it did not.
- Visual errors in image and multimodal generation: A model creates impossible objects, wrong labels, extra limbs, broken diagrams, or text that looks like words but is not readable.
For developers, the hardest hallucinations are often not spectacular failures. They are ordinary-looking answers that pass a quick glance. A support answer may cite the right product but the wrong refund period. A legal assistant may identify the correct jurisdiction but apply an outdated rule. A code assistant may invent an API parameter that matches naming conventions but is not supported by the library.
These examples show why hallucination testing should include real task data, adversarial prompts, stale information, incomplete context, and edge cases. A system that works on clean demos may still fail when users bring messy documents, conflicting instructions, or questions outside the knowledge base.
Why Hallucinations Become A Serious AI Problem
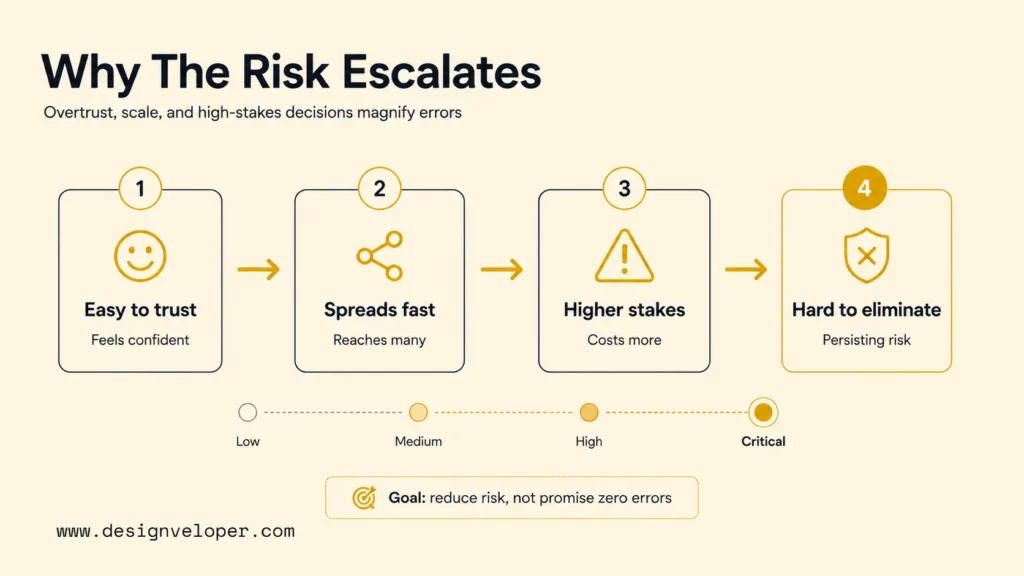
Hallucinations become a serious AI problem when generated output affects real decisions. The same behavior that seems harmless in a chat experiment can become costly in production because AI tools scale quickly. One wrong answer can be copied into many workflows, sent to many customers, or used as the basis for later automation.
The risk grows when a hallucination moves from private draft to business action. The following stack is a useful review shortcut for product teams.
Hallucination risk stack
Low: private brainstorm, reversible draft, no factual decision.
Medium: internal summary, source review needed, limited business impact.
High: customer-facing answer, code suggestion, financial or policy interpretation.
Critical: medical, legal, security, payment, access, or automated workflow action.
A risk stack keeps the discussion practical. Low-risk tasks may only need user review. Critical workflows need verified sources, constrained tools, audit logs, approval gates, monitoring, and rollback plans before launch.
Confident Output Is Easy For People To Trust
Confident output is easy for people to trust because humans are used to associating clarity with competence. A model that answers quickly, formats cleanly, and uses expert language can feel authoritative. That creates a trust gap: the user’s confidence may rise faster than the system’s actual reliability.
Good AI product design should slow down overtrust in high-risk contexts. The interface can show sources, uncertainty labels, confidence warnings, or “needs review” states. The workflow can require approval before customer-facing messages, payments, medical recommendations, legal language, or operational changes are executed.
Errors Spread Quickly In Search And Research Workflows
Errors spread quickly in search and research workflows because AI answers are often used as shortcuts. A user may ask a chatbot for a summary, then paste the result into a slide, article, report, or customer response. If the answer includes a false source or unsupported claim, the error can become part of the organization’s working knowledge.
This is one reason retrieval design matters. A research assistant should cite accessible sources, separate quoted evidence from generated interpretation, and make it easy to open the original document. A search-like experience without verifiable links can look efficient while quietly weakening the quality of decisions.
High-Stakes Use Cases Carry Higher Consequences
High-stakes use cases carry higher consequences because the cost of a false answer is uneven. A wrong restaurant suggestion may be annoying. A wrong drug interaction, contract clause, security fix, tax interpretation, or financial recommendation can harm people or businesses. The technology may be similar, but the risk profile is not.
NIST’s AI Risk Management Framework and the Generative AI Profile, NIST AI 600-1 encourage organizations to identify, measure, manage, and govern AI risks. For hallucinations, that means matching controls to impact. A low-risk draft-writing tool may need light review. A clinical, legal, financial, or security workflow needs stricter evidence, logging, testing, access control, and human oversight.
Hallucinations Are Hard To Eliminate Completely
Hallucinations are hard to eliminate completely because generative models are probabilistic, context-limited, and dependent on the information available at inference time. Better models can reduce the rate of hallucination. Better prompts can help. Retrieval and tools can help more. But no serious team should promise that hallucinations will never happen.
The practical goal is risk reduction. Teams can make hallucinations less frequent, easier to detect, less likely to reach users, and less damaging when they occur. That requires system-level safeguards, not only clever wording in a prompt.
AI Hallucinations Across LLMs And Chatbots
AI hallucinations is the broadest term across generative AI systems. It can describe false output from text models, image models, audio systems, multimodal assistants, code generators, and AI agents. The behavior may look different across modalities, but the underlying risk is similar: the system produces something that appears meaningful without being grounded in reality or the supplied evidence.
LLM hallucination refers more specifically to false or unsupported language-model output. This includes wrong answers in chatbot conversations, invented facts in summaries, incorrect code explanations, fabricated citations, and unsupported reasoning. LLM hallucination is especially important for business applications because language models are often connected to knowledge bases, ticket systems, CRMs, document stores, and internal workflows.
ChatGPT hallucination is a product-level example of the same underlying behavior. ChatGPT can be very useful for drafting, brainstorming, explaining code, and summarizing information, but users still need verification when accuracy matters. The term “ChatGPT hallucination” is popular because many people first experienced LLM behavior through chat interfaces, yet the risk is not limited to one product or vendor.
For AI teams, the naming matters less than the workflow. Whether the product is a customer support chatbot, an internal assistant, a coding agent, or a document analysis tool, the design question is the same: what evidence does the model have, what actions can it take, how is output checked, and what happens when the model is uncertain?
Reducing Hallucination Risk In Real Systems
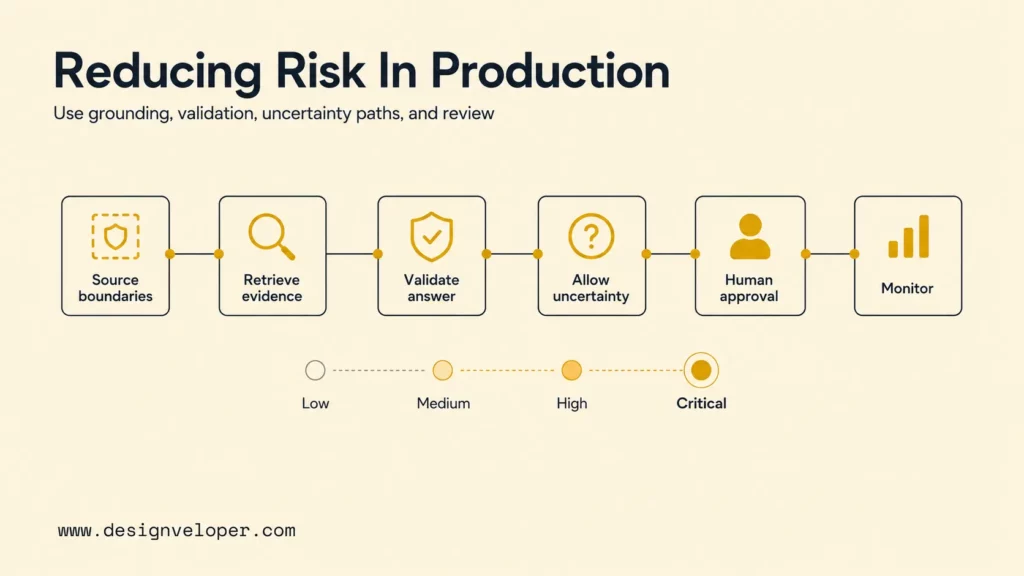
Reducing hallucination risk in real systems requires a combination of grounding, retrieval, decomposition, uncertainty handling, testing, and human review. A prompt can improve behavior, but production reliability comes from architecture and process. The safest systems are easier to inspect, not just easier to read.
A practical hallucination-reduction plan should combine product, engineering, and governance controls. The strongest setups usually include the following safeguards:
- Source boundaries: define which documents, databases, web pages, APIs, or tools the model may use for each task.
- Retrieval evaluation: test whether the system retrieves the right evidence before judging the generated answer.
- Answer validation: check citations, required fields, numerical claims, unsupported assertions, and tool-result consistency before output is shown.
- Uncertainty paths: let the system say it cannot answer from the available evidence, ask a follow-up question, or escalate to a person.
- Human approval: keep people in control of high-impact messages, record changes, payments, legal language, medical guidance, and security actions.
- Monitoring and incident review: log prompts, retrieved context, tool calls, outputs, user feedback, and confirmed failures so the team can improve the system.
Agentic systems need the same controls with stricter boundaries because agents can act, not only answer. Designveloper’s guide to agentic AI security covers tool access, memory protection, and governance patterns that reduce the chance of one hallucinated step becoming a larger workflow incident.
Ground Answers In Trusted Sources
Grounding means connecting the model’s answer to trusted source material. That source may be a document, database, policy page, search result, product catalog, code repository, or customer record. Google Cloud’s grounding documentation explains that grounding can reduce hallucinations by anchoring responses to data sources and giving users auditability through source links.
Retrieval-augmented generation is one common grounding pattern. The system searches a trusted knowledge base, selects relevant passages, passes those passages into the prompt, and asks the model to answer from that evidence. This works best when the retrieval system has good chunking, ranking, freshness, permissions, and citation handling. Weak retrieval can still give the model irrelevant or outdated context. For implementation teams, Designveloper’s RAG best practices guide explains why chunking, ranking, freshness, and evaluation matter when retrieval is used to reduce hallucinations.
Break Complex Tasks Into Smaller Verification Steps
Complex tasks should be broken into smaller verification steps because one large answer is difficult to inspect. A legal document assistant might first identify relevant clauses, then summarize each clause, then produce a risk memo with citations. A coding assistant might inspect the API documentation, propose a patch, run tests, and report the exact results. A support agent might retrieve policy, check account status, draft a reply, and wait for human approval.
Breaking work into steps also creates logs. Logs help teams audit what the model saw, what tools it used, what evidence supported the answer, and where an error entered the workflow. That makes hallucination incidents easier to debug and reduces repeated failures.
Let The Model Say It Does Not Know
AI systems need permission to say “I do not know.” If every evaluation rewards an answer and punishes abstention, models learn to guess. OpenAI’s hallucination research argues that evaluation methods should avoid rewarding lucky guesses over appropriate uncertainty. In product terms, that means the application should support fallback states such as “I cannot find this in the provided sources” or “This needs human review.”
Uncertainty is not a failure when the alternative is a fabricated answer. A good business assistant can ask for missing context, request access to a source, suggest a safe next step, or route the task to a human. That behavior may feel less magical, but it is more trustworthy.
Keep Human Review For High-Risk Decisions
Human review should remain in high-risk decisions. AI can draft, retrieve, compare, classify, and summarize, but people should approve outputs that affect health, money, legal rights, security, employment, brand reputation, or irreversible operations. Review is especially important when a system acts on behalf of a user, such as sending emails, updating records, approving refunds, changing access, or triggering workflows.
At Designveloper, this is how we frame practical AI delivery: useful automation should still respect workflow ownership, permissions, evidence, monitoring, and approval gates. Our AI development services focus on AI systems inside real products and operations, while our delivery process keeps discovery, engineering, testing, deployment, and support connected. For hallucination risk, that means designing retrieval, validation, audit logs, human approval, and post-launch monitoring from the start.
Reliable AI Depends On Grounding And Verification

Reliable AI depends on grounding and verification because language fluency is not the same as truth. The safest AI systems are easier to check, not just easier to read. They show sources, preserve context, log tool use, separate evidence from interpretation, and make uncertain outputs visible before they affect users.
Better grounding, retrieval, and review workflows usually matter more than confident wording. A polished answer without evidence can still be wrong. A shorter answer with source links, limits, and a clear path to verification is often more valuable in business workflows. Teams should optimize for traceability, not only response style.
Teams using AI in production need system-level safeguards, not prompt tweaks alone. That includes knowledge-base quality, retrieval evaluation, source freshness, permission checks, output validation, human-in-the-loop review, monitoring, incident handling, and regular testing against real user questions. Hallucination risk is not a reason to avoid AI. It is a reason to build AI like production software.
Before an AI feature goes live, teams can use a simple acceptance checklist to decide whether hallucination risk is controlled enough for the workflow.
| Acceptance check | Pass signal | Warning sign |
|---|---|---|
| Evidence quality | The answer links to current, accessible, trusted sources. | The answer relies on model memory or vague references. |
| Retrieval quality | Test questions retrieve the right passages, records, or API outputs. | The system retrieves irrelevant chunks or misses known documents. |
| Action safety | High-impact tool calls require explicit approval and leave logs. | The agent can update records or send messages without review. |
| User clarity | The interface separates evidence, model interpretation, and uncertainty. | The interface presents generated text as unquestionable truth. |
| Operational review | Failures are logged, triaged, and used to update tests or knowledge sources. | Teams only discover errors through customer complaints. |
For business leaders, the practical takeaway is simple: do not ask whether an AI model can write a convincing answer. Ask whether the system can show where the answer came from, admit when evidence is missing, and keep risky decisions under review. That is the difference between a demo chatbot and a reliable AI workflow.
FAQs About AI Hallucinations

The following answers summarize the questions teams most often ask before using LLMs, chatbots, or AI agents in production workflows.
Can ChatGPT Hallucinate Even When It Sounds Certain?
Yes. ChatGPT can hallucinate even when it sounds certain. Confidence in wording does not prove factual accuracy. Users should verify important claims with sources, especially when the answer involves recent events, legal or medical information, financial decisions, technical implementation details, or private business data.
Why Does ChatGPT Hallucinate?
ChatGPT can hallucinate because large language models generate likely text from patterns and context. If the needed information is missing, outdated, ambiguous, or unsupported by sources, the model may still produce a fluent answer. Hallucination risk increases when prompts demand an answer, discourage uncertainty, or ask about facts the model cannot verify.
How Do You Know If An AI Is Hallucinating?
You know an AI may be hallucinating when claims cannot be traced to reliable sources, citations do not exist, links fail, numbers differ from original documents, summaries change important meaning, or the system claims to have performed actions without tool logs. Verification should compare AI output against primary sources, records, tests, or human expertise.
Can AI Hallucinations Be Prevented Completely?
No. AI hallucinations cannot be prevented completely in all generative AI systems. Better models, grounding, retrieval, tool use, evaluation, and review can reduce the risk, but teams should assume some residual risk remains. The goal is to make hallucinations rarer, more detectable, and less harmful.
How To Avoid AI Hallucinations?
To avoid AI hallucinations, ground answers in trusted sources, retrieve current context, ask the model to cite evidence, allow uncertainty, verify important claims, break complex tasks into smaller steps, and keep human review for high-risk outputs. For production AI, combine prompt guidance with system controls, monitoring, and regular evaluation.
AI hallucinations are manageable when teams treat them as a product and engineering risk. With grounding, verification, and human oversight, organizations can use LLMs and chatbots more safely while still gaining speed, scale, and better access to knowledge.


{kind=link}